 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreventing Imitation Learning with Adversarial Policy Ensembles
Paper and Code
Jan 31, 2020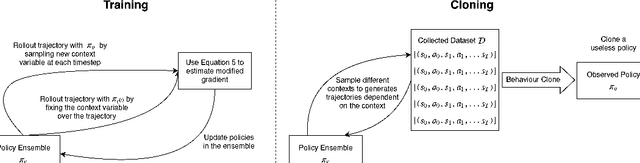


Imitation learning can reproduce policies by observing experts, which poses a problem regarding policy privacy. Policies, such as human, or policies on deployed robots, can all be cloned without consent from the owners. How can we protect against external observers cloning our proprietary policies? To answer this question we introduce a new reinforcement learning framework, where we train an ensemble of near-optimal policies, whose demonstrations are guaranteed to be useless for an external observer. We formulate this idea by a constrained optimization problem, where the objective is to improve proprietary policies, and at the same time deteriorate the virtual policy of an eventual external observer. We design a tractable algorithm to solve this new optimization problem by modifying the standard policy gradient algorithm. Our formulation can be interpreted in lenses of confidentiality and adversarial behaviour, which enables a broader perspective of this work. We demonstrate the existence of "non-clonable" ensembles, providing a solution to the above optimization problem, which is calculated by our modified policy gradient algorithm. To our knowledge, this is the first work regarding the protection of policies in Reinforcement Learning.