 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePseudo-Bidirectional Decoding for Local Sequence Transduction
Paper and Code
Feb 12, 2020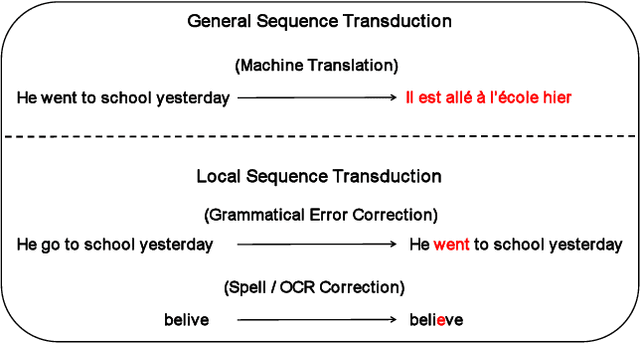
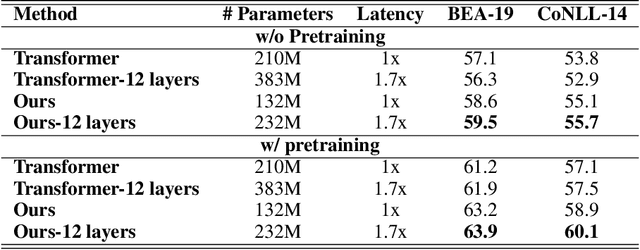
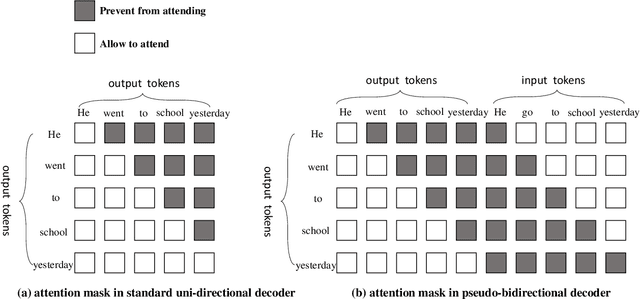
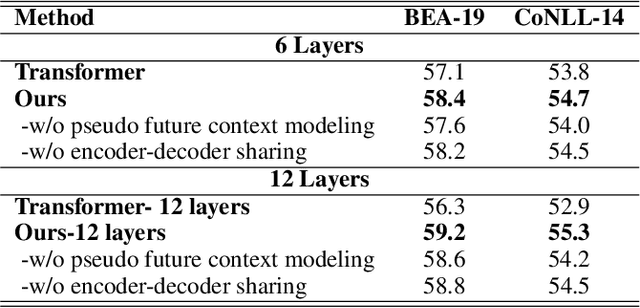
Local sequence transduction (LST) tasks are sequence transduction tasks where there exists massive overlapping between the source and target sequences, such as Grammatical Error Correction (GEC) and spell or OCR correction. Previous work generally tackles LST tasks with standard sequence-to-sequence (seq2seq) models that generate output tokens from left to right and suffer from the issue of unbalanced outputs. Motivated by the characteristic of LST tasks, in this paper, we propose a simple but versatile approach named Pseudo-Bidirectional Decoding (PBD) for LST tasks. PBD copies the corresponding representation of source tokens to the decoder as pseudo future context to enable the decoder to attends to its bi-directional context. In addition, the bidirectional decoding scheme and the characteristic of LST tasks motivate us to share the encoder and the decoder of seq2seq models. The proposed PBD approach provides right side context information for the decoder and models the inductive bias of LST tasks, reducing the number of parameters by half and providing good regularization effects. Experimental results on several benchmark datasets show that our approach consistently improves the performance of standard seq2seq models on LST tasks.