 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemi-supervised ASR by End-to-end Self-training
Paper and Code
Jan 24, 2020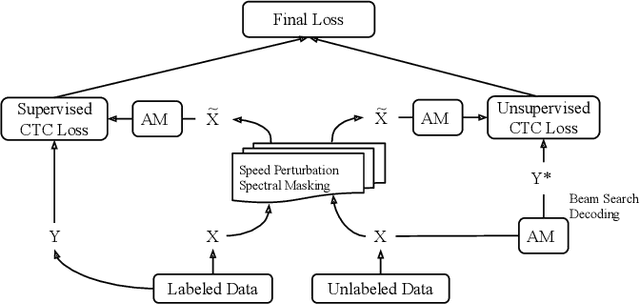
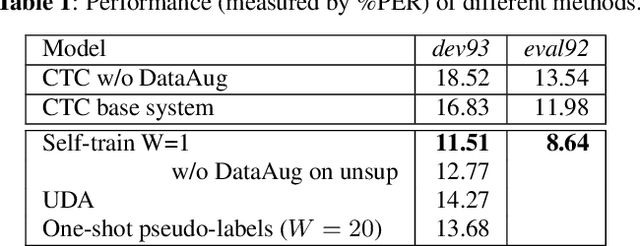
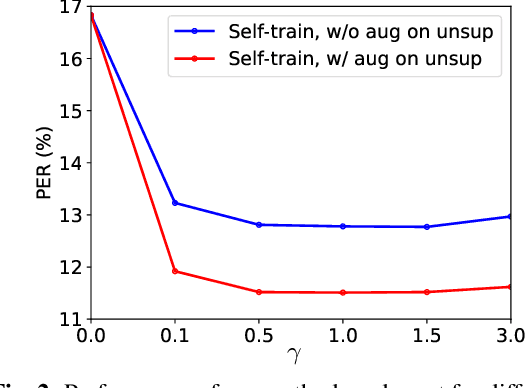
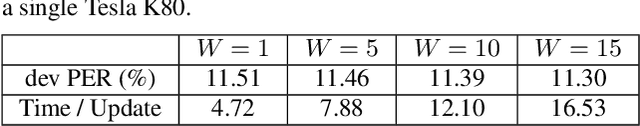
While deep learning based end-to-end automatic speech recognition (ASR) systems have greatly simplified modeling pipelines, they suffer from the data sparsity issue. In this work, we propose a self-training method with an end-to-end system for semi-supervised ASR. Starting from a Connectionist Temporal Classification (CTC) system trained on the supervised data, we iteratively generate pseudo-labels on a mini-batch of unsupervised utterances with the current model, and use the pseudo-labels to augment the supervised data for immediate model update. Our method retains the simplicity of end-to-end ASR systems, and can be seen as performing alternating optimization over a well-defined learning objective. We also perform empirical investigations of our method, regarding the effect of data augmentation, decoding beamsize for pseudo-label generation, and freshness of pseudo-labels. On a commonly used semi-supervised ASR setting with the WSJ corpus, our method gives 14.4% relative WER improvement over a carefully-trained base system with data augmentation, reducing the performance gap between the base system and the oracle system by 50%.