 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Layer Content Interaction Through Quaternion Product For Visual Question Answering
Paper and Code
Feb 16, 2020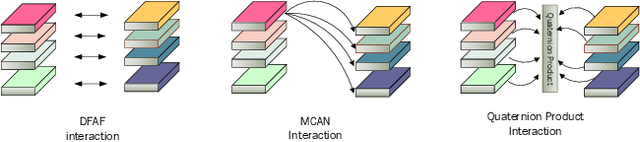
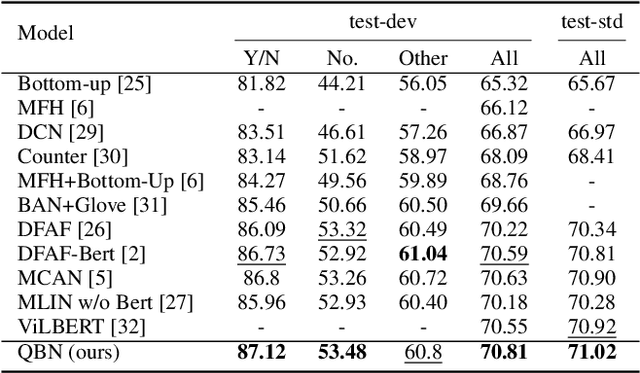
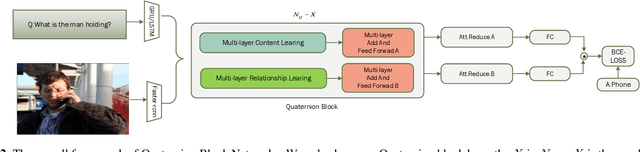
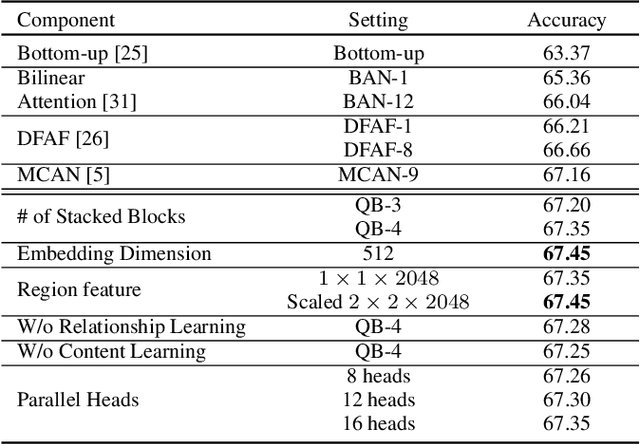
Multi-modality fusion technologies have greatly improved the performance of neural network-based Video Description/Caption, Visual Question Answering (VQA) and Audio Visual Scene-aware Dialog (AVSD) over the recent years. Most previous approaches only explore the last layers of multiple layer feature fusion while omitting the importance of intermediate layers. To solve the issue for the intermediate layers, we propose an efficient Quaternion Block Network (QBN) to learn interaction not only for the last layer but also for all intermediate layers simultaneously. In our proposed QBN, we use the holistic text features to guide the update of visual features. In the meantime, Hamilton quaternion products can efficiently perform information flow from higher layers to lower layers for both visual and text modalities. The evaluation results show our QBN improved the performance on VQA 2.0, even though using surpass large scale BERT or visual BERT pre-trained models. Extensive ablation study has been carried out to testify the influence of each proposed module in this study.