 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedDANE: A Federated Newton-Type Method
Paper and Code

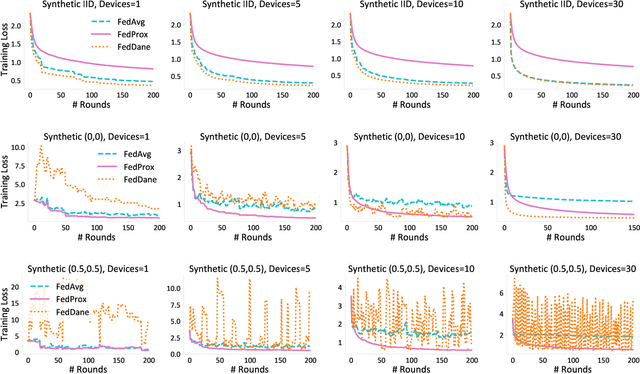
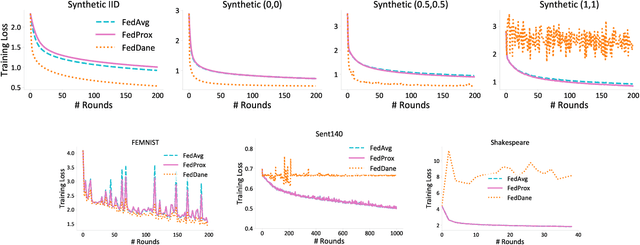
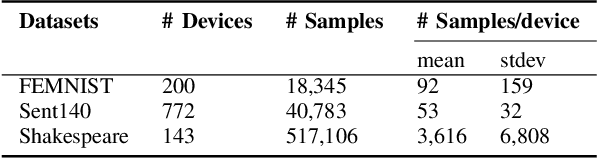
Federated learning aims to jointly learn statistical models over massively distributed remote devices. In this work, we propose FedDANE, an optimization method that we adapt from DANE, a method for classical distributed optimization, to handle the practical constraints of federated learning. We provide convergence guarantees for this method when learning over both convex and non-convex functions. Despite encouraging theoretical results, we find that the method has underwhelming performance empirically. In particular, through empirical simulations on both synthetic and real-world datasets, FedDANE consistently underperforms baselines of FedAvg and FedProx in realistic federated settings. We identify low device participation and statistical device heterogeneity as two underlying causes of this underwhelming performance, and conclude by suggesting several directions of future work.