 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDBP: Discrimination Based Block-Level Pruning for Deep Model Acceleration
Paper and Code
Dec 21, 2019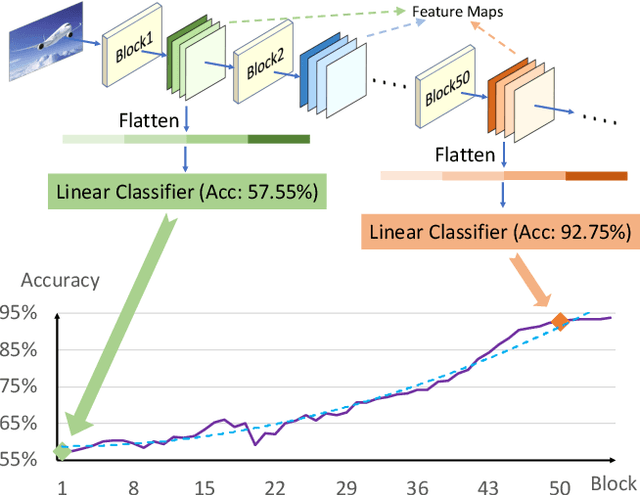
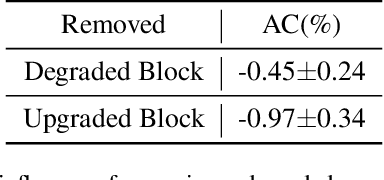
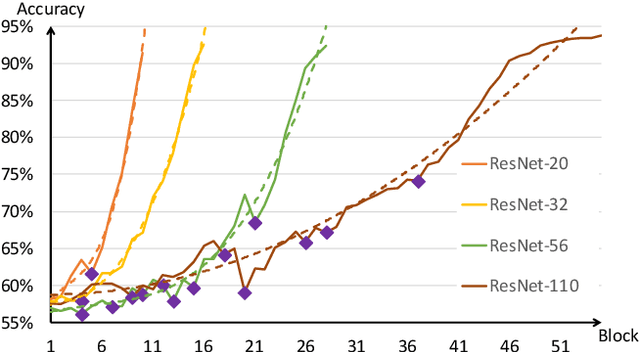
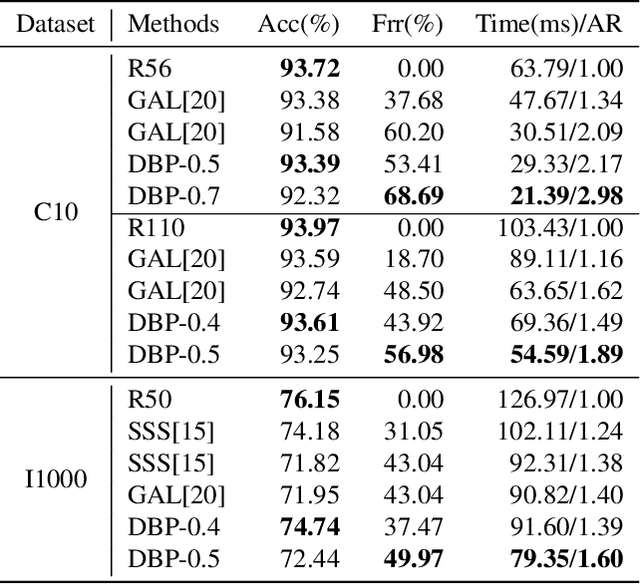
Neural network pruning is one of the most popular methods of accelerating the inference of deep convolutional neural networks (CNNs). The dominant pruning methods, filter-level pruning methods, evaluate their performance through the reduction ratio of computations and deem that a higher reduction ratio of computations is equivalent to a higher acceleration ratio in terms of inference time. However, we argue that they are not equivalent if parallel computing is considered. Given that filter-level pruning only prunes filters in layers and computations in a layer usually run in parallel, most computations reduced by filter-level pruning usually run in parallel with the un-reduced ones. Thus, the acceleration ratio of filter-level pruning is limited. To get a higher acceleration ratio, it is better to prune redundant layers because computations of different layers cannot run in parallel. In this paper, we propose our Discrimination based Block-level Pruning method (DBP). Specifically, DBP takes a sequence of consecutive layers (e.g., Conv-BN-ReLu) as a block and removes redundant blocks according to the discrimination of their output features. As a result, DBP achieves a considerable acceleration ratio by reducing the depth of CNNs. Extensive experiments show that DBP has surpassed state-of-the-art filter-level pruning methods in both accuracy and acceleration ratio. Our code will be made available soon.