 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Convolution: Attention over Convolution Kernels
Paper and Code
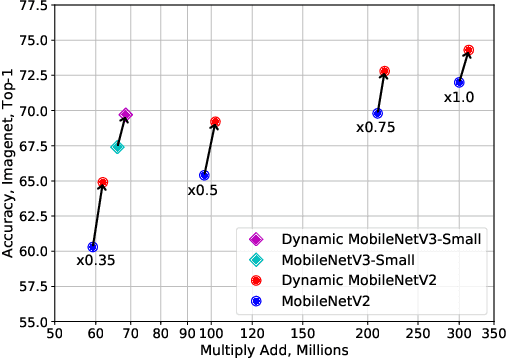
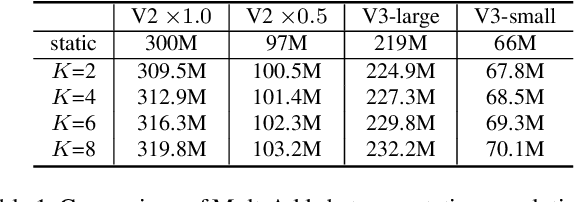
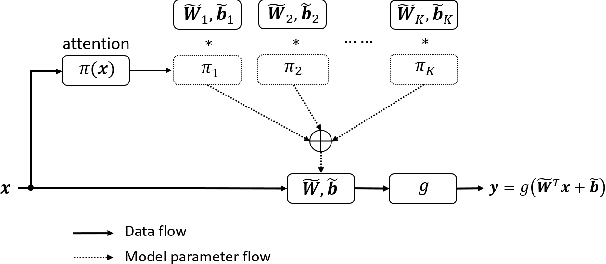
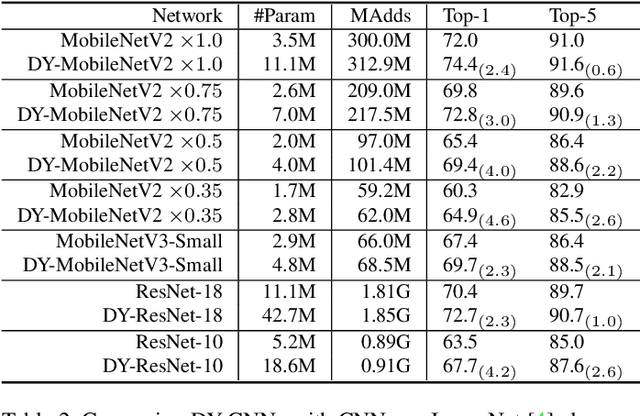
Light-weight convolutional neural networks (CNNs) suffer performance degradation as their low computational budgets constrain both the depth (number of convolution layers) and width (number of channels) of CNNs, resulting in limited representation capability. To address this issue, we present dynamic convolution, a new design that increases model complexity without increasing the network depth or width. Instead of using a single convolution kernel per layer, dynamic convolution aggregates multiple parallel convolution kernels dynamically based upon their attentions, which are input dependent. Assembling multiple kernels is not only computationally efficient due to the small kernel size, but also has more representation power since these kernels are aggregated in a non-linear way via attention. By simply using dynamic convolution for the state-of-the-art architecture MobilenetV3-Small, the top-1 accuracy on ImageNet classification is boosted by 2.3% with only 4% additional FLOPs and 2.9 AP gain is achieved on COCO keypoint detection.