 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlockwisely Supervised Neural Architecture Search with Knowledge Distillation
Paper and Code
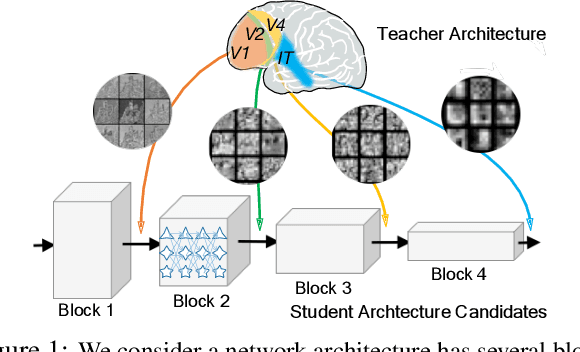
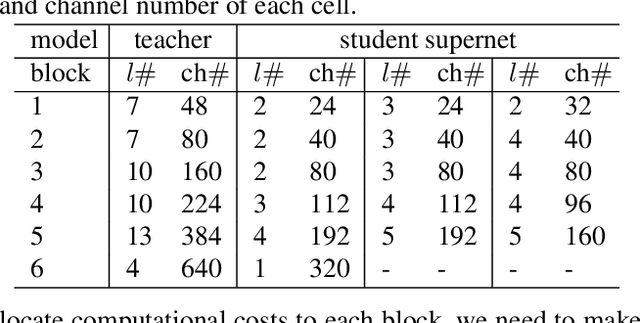
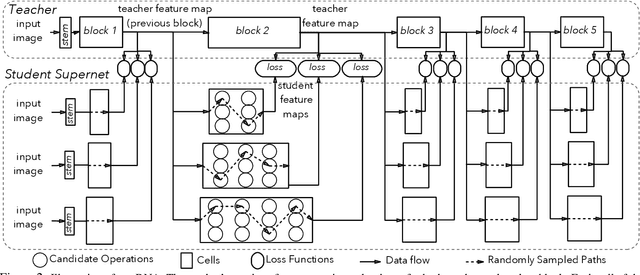
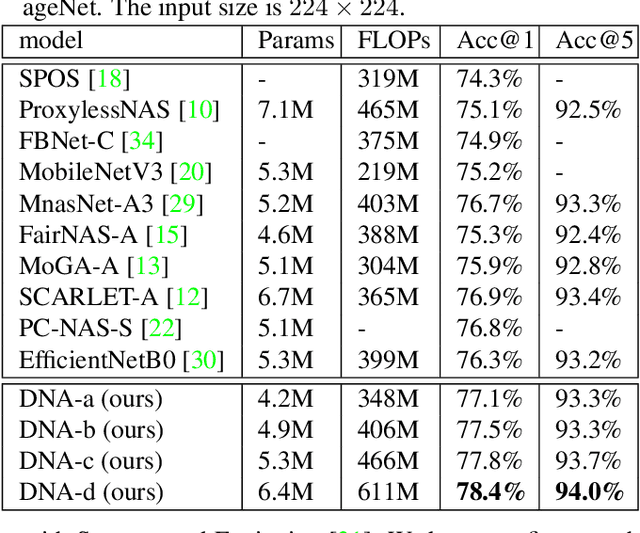
Neural Architecture Search (NAS), aiming at automatically designing network architectures by machines, is hoped and expected to bring about a new revolution in machine learning. Despite these high expectation, the effectiveness and efficiency of existing NAS solutions are unclear, with some recent works going so far as to suggest that many existing NAS solutions are no better than random architecture selection. The inefficiency of NAS solutions may be attributed to inaccurate architecture evaluation. Specifically, to speed up NAS, recent works have proposed under-training different candidate architectures in a large search space concurrently by using shared network parameters; however, this has resulted in incorrect architecture ratings and furthered the ineffectiveness of NAS. In this work, we propose to modularize the large search space of NAS into blocks to ensure that the potential candidate architectures are fully trained; this reduces the representation shift caused by the shared parameters and leads to the correct rating of the candidates. Thanks to the block-wise search, we can also evaluate all of the candidate architectures within a block. Moreover, we find that the knowledge of a network model lies not only in the network parameters but also in the network architecture. Therefore, we propose to distill the neural architecture (DNA) knowledge from a teacher model as the supervision to guide our block-wise architecture search, which significantly improves the effectiveness of NAS. Remarkably, the capacity of our searched architecture has exceeded the teacher model, demonstrating the practicability and scalability of our method. Finally, our method achieves a state-of-the-art 78.4\% top-1 accuracy on ImageNet in a mobile setting, which is about a 2.1\% gain over EfficientNet-B0. All of our searched models along with the evaluation code are available online.