 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Corpus for Low-Resourced Sindhi Language with Word Embeddings
Paper and Code
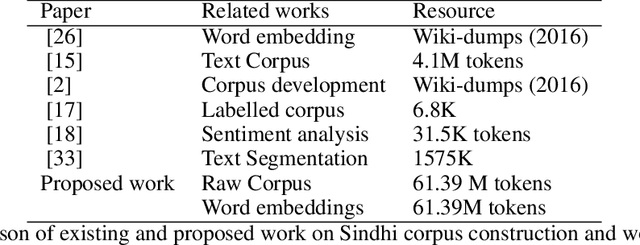
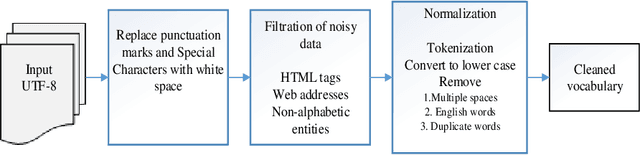
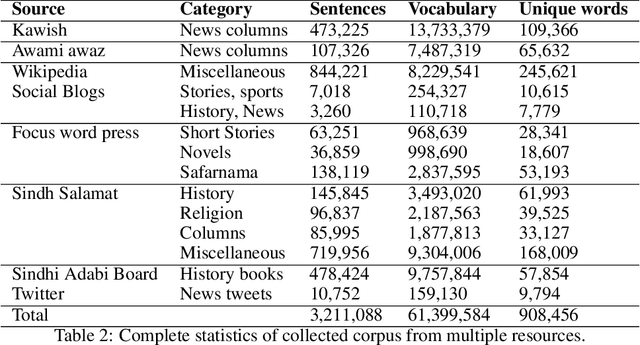
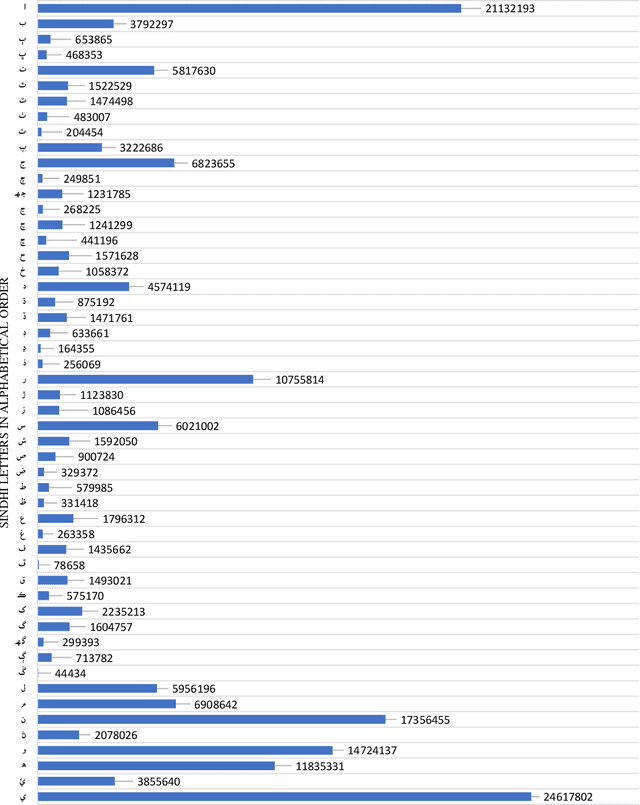
Representing words and phrases into dense vectors of real numbers which encode semantic and syntactic properties is a vital constituent in natural language processing (NLP). The success of neural network (NN) models in NLP largely rely on such dense word representations learned on the large unlabeled corpus. Sindhi is one of the rich morphological language, spoken by large population in Pakistan and India lacks corpora which plays an essential role of a test-bed for generating word embeddings and developing language independent NLP systems. In this paper, a large corpus of more than 61 million words is developed for low-resourced Sindhi language for training neural word embeddings. The corpus is acquired from multiple web-resources using web-scrappy. Due to the unavailability of open source preprocessing tools for Sindhi, the prepossessing of such large corpus becomes a challenging problem specially cleaning of noisy data extracted from web resources. Therefore, a preprocessing pipeline is employed for the filtration of noisy text. Afterwards, the cleaned vocabulary is utilized for training Sindhi word embeddings with state-of-the-art GloVe, Skip-Gram (SG), and Continuous Bag of Words (CBoW) word2vec algorithms. The intrinsic evaluation approach of cosine similarity matrix and WordSim-353 are employed for the evaluation of generated Sindhi word embeddings. Moreover, we compare the proposed word embeddings with recently revealed Sindhi fastText (SdfastText) word representations. Our intrinsic evaluation results demonstrate the high quality of our generated Sindhi word embeddings using SG, CBoW, and GloVe as compare to SdfastText word representations.