 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFactorized Multimodal Transformer for Multimodal Sequential Learning
Paper and Code
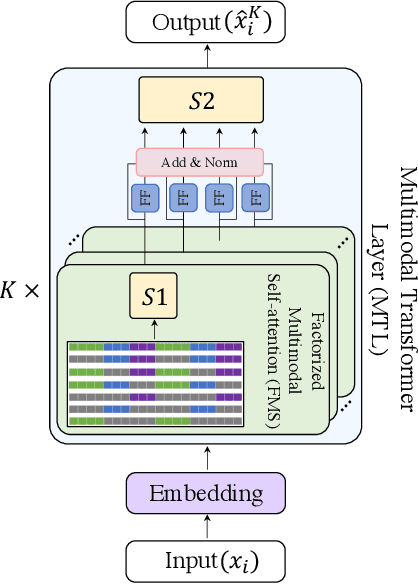
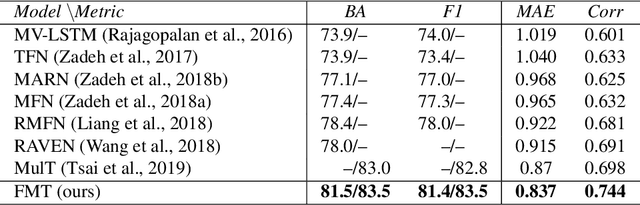
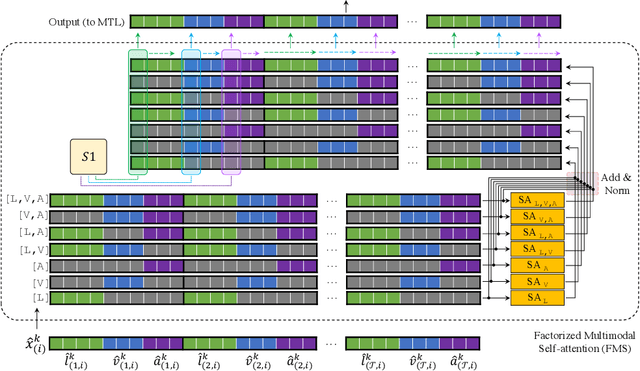
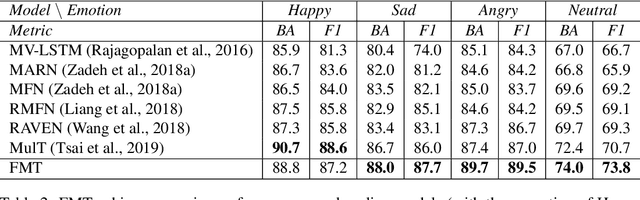
The complex world around us is inherently multimodal and sequential (continuous). Information is scattered across different modalities and requires multiple continuous sensors to be captured. As machine learning leaps towards better generalization to real world, multimodal sequential learning becomes a fundamental research area. Arguably, modeling arbitrarily distributed spatio-temporal dynamics within and across modalities is the biggest challenge in this research area. In this paper, we present a new transformer model, called the Factorized Multimodal Transformer (FMT) for multimodal sequential learning. FMT inherently models the intramodal and intermodal (involving two or more modalities) dynamics within its multimodal input in a factorized manner. The proposed factorization allows for increasing the number of self-attentions to better model the multimodal phenomena at hand; without encountering difficulties during training (e.g. overfitting) even on relatively low-resource setups. All the attention mechanisms within FMT have a full time-domain receptive field which allows them to asynchronously capture long-range multimodal dynamics. In our experiments we focus on datasets that contain the three commonly studied modalities of language, vision and acoustic. We perform a wide range of experiments, spanning across 3 well-studied datasets and 21 distinct labels. FMT shows superior performance over previously proposed models, setting new state of the art in the studied datasets.