 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeREFIT: a Unified Watermark Removal Framework for Deep Learning Systems with Limited Data
Paper and Code
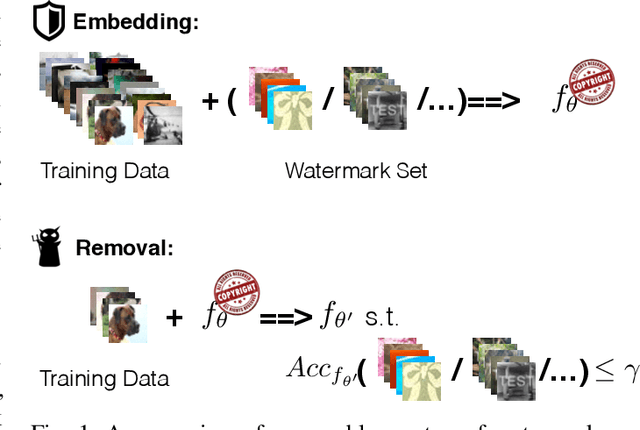
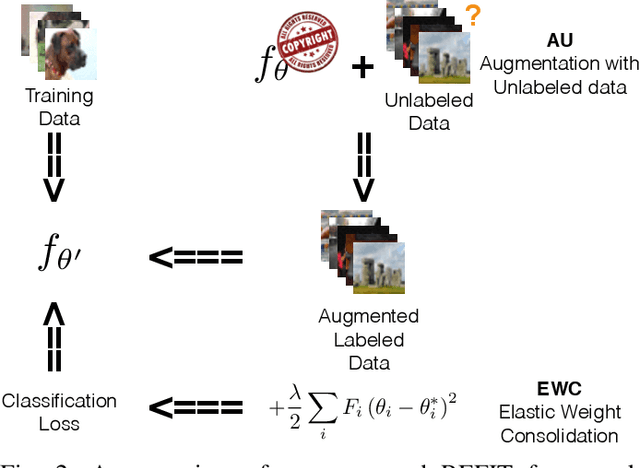
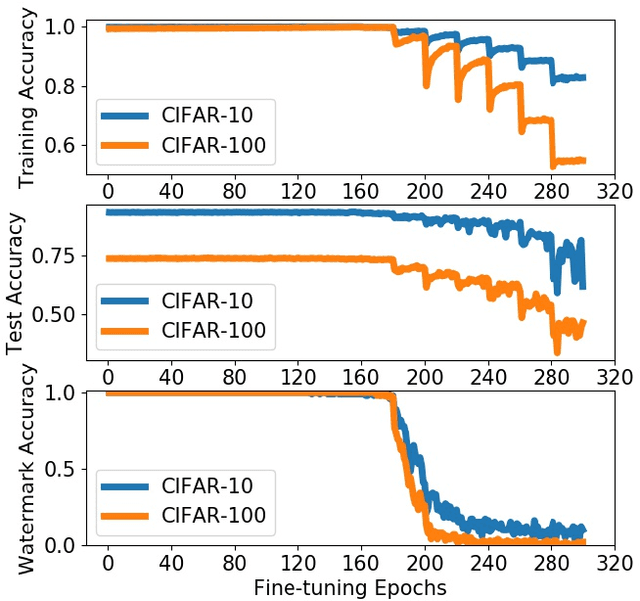

Deep neural networks (DNNs) have achieved tremendous success in various fields; however, training these models from scratch could be computationally expensive and requires a lot of training data. Recent work has explored different watermarking techniques to protect the pre-trained deep neural networks from potential copyright infringements; however, they could be vulnerable to adversaries who aim at removing the watermarks. In this work, we propose REFIT, a unified watermark removal framework based on fine-tuning, which does not rely on the knowledge of the watermarks and even the watermarking schemes. Firstly, we demonstrate that by properly designing the learning rate schedule for fine-tuning, an adversary is always able to remove the watermarks. Furthermore, we conduct a comprehensive study of a realistic attack scenario where the adversary has limited training data. To effectively remove the watermarks without compromising the model functionality under this weak threat model, we propose to incorporate two techniques: (1) an adaption of the elastic weight consolidation (EWC) algorithm, which is originally proposed for mitigating the catastrophic forgetting phenomenon; and (2) unlabeled data augmentation (AU), where we leverage auxiliary unlabeled data from other sources. Our extensive evaluation shows the effectiveness of REFIT against diverse watermark embedding schemes. In particular, both EWC and AU significantly decrease the amount of labeled training data needed for effective watermark removal, and the unlabeled data samples used for AU do not necessarily need to be drawn from the same distribution as the benign data for model evaluation. The experimental results demonstrate that our fine-tuning based watermark removal attacks could pose real threats to the copyright of pre-trained models, and thus highlights the importance of further investigation of the watermarking problem.