 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyntax-Infused Transformer and BERT models for Machine Translation and Natural Language Understanding
Paper and Code
Nov 10, 2019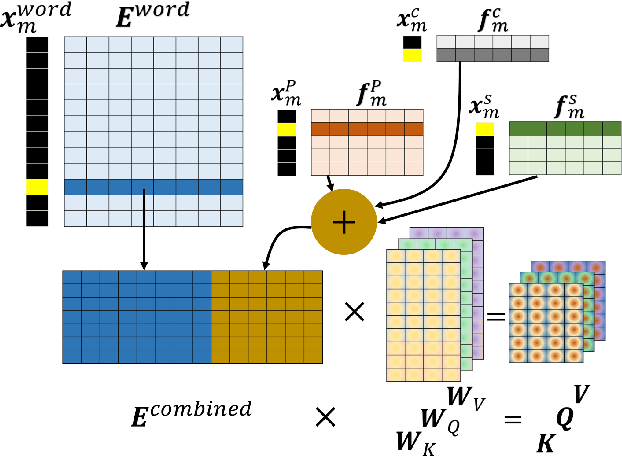
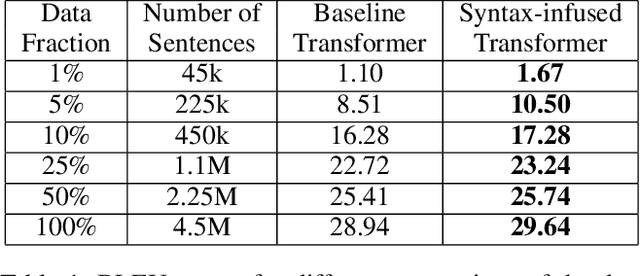
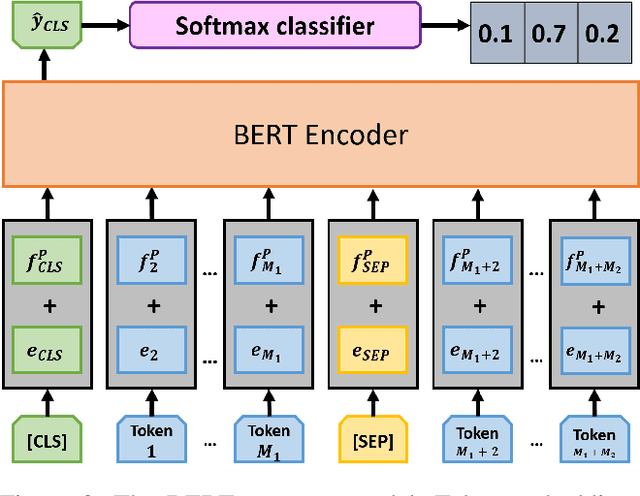

Attention-based models have shown significant improvement over traditional algorithms in several NLP tasks. The Transformer, for instance, is an illustrative example that generates abstract representations of tokens inputted to an encoder based on their relationships to all tokens in a sequence. Recent studies have shown that although such models are capable of learning syntactic features purely by seeing examples, explicitly feeding this information to deep learning models can significantly enhance their performance. Leveraging syntactic information like part of speech (POS) may be particularly beneficial in limited training data settings for complex models such as the Transformer. We show that the syntax-infused Transformer with multiple features achieves an improvement of 0.7 BLEU when trained on the full WMT 14 English to German translation dataset and a maximum improvement of 1.99 BLEU points when trained on a fraction of the dataset. In addition, we find that the incorporation of syntax into BERT fine-tuning outperforms baseline on a number of downstream tasks from the GLUE benchmark.