 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Self-Attention: An Interpretable Self-Attentive Encoder-Decoder Parser
Paper and Code
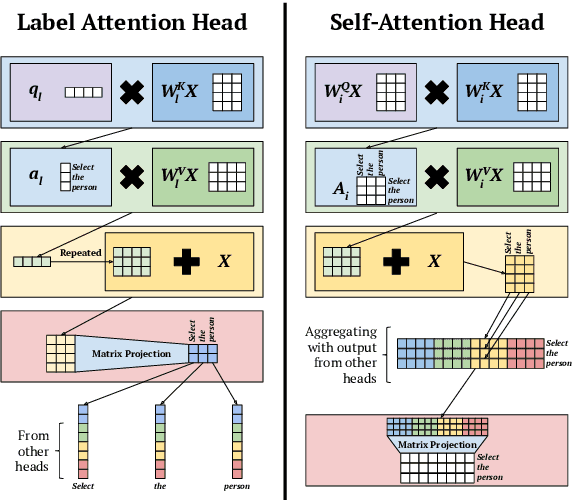
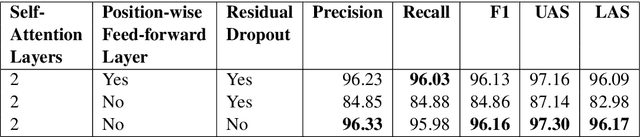
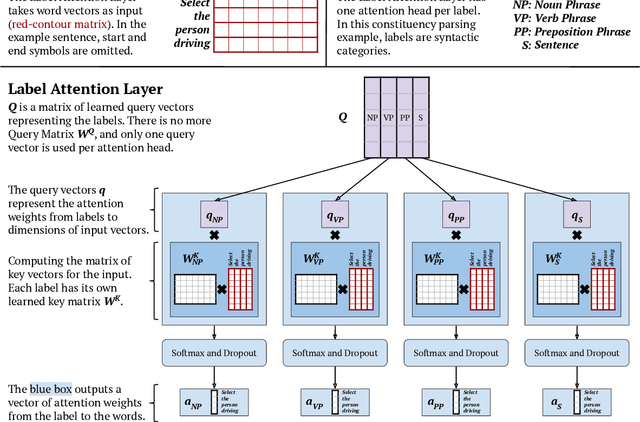
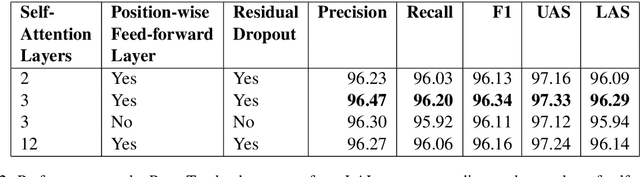
Attention mechanisms have improved the performance of NLP tasks while providing for appearance of model interpretability. Self-attention is currently widely used in NLP models, however it is difficult to interpret due to the numerous attention distributions. We hypothesize that model representations can benefit from label-specific information, while facilitating interpretation of predictions. We introduce the Label Attention Layer: a new form of self-attention where attention heads represent labels. We validate our hypothesis by running experiments in constituency and dependency parsing and show our new model obtains new state-of-the-art results for both tasks on the English Penn Treebank. Our neural parser obtains 96.34 F1 score for constituency parsing, and 97.33 UAS and 96.29 LAS for dependency parsing. Additionally, our model requires fewer layers, therefore, fewer parameters compared to existing work.