 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMinimalistic Attacks: How Little it Takes to Fool a Deep Reinforcement Learning Policy
Paper and Code


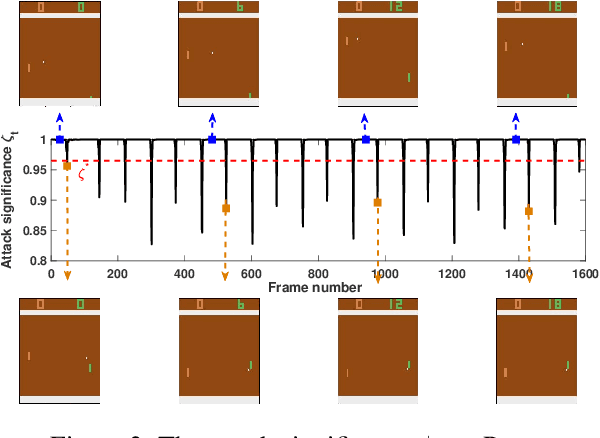
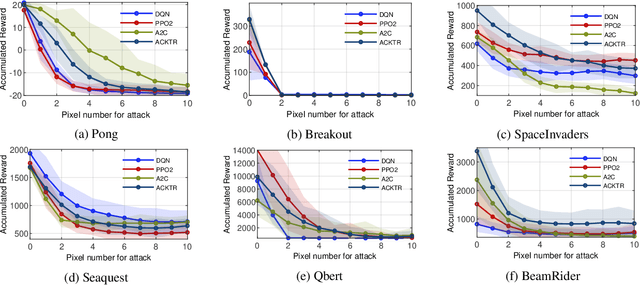
Recent studies have revealed that neural network-based policies can be easily fooled by adversarial examples. However, while most prior works analyze the effects of perturbing every pixel of every frame assuming white-box policy access, in this paper we take a more restrictive view towards adversary generation - with the goal of unveiling the limits of a model's vulnerability. In particular, we explore minimalistic attacks by defining three key settings: (1) black-box policy access: where the attacker only has access to the input (state) and output (action probability) of an RL policy; (2) fractional-state adversary: where only several pixels are perturbed, with the extreme case being a single-pixel adversary; and (3) tactically-chanced attack: where only significant frames are tactically chosen to be attacked. We formulate the adversarial attack by accommodating the three key settings and explore their potency on six Atari games by examining four fully trained state-of-the-art policies. In Breakout, for example, we surprisingly find that: (i) all policies showcase significant performance degradation by merely modifying 0.01% of the input state, and (ii) the policy trained by DQN is totally deceived by perturbation to only 1% frames.