 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncremental Text-to-Speech Synthesis with Prefix-to-Prefix Framework
Paper and Code
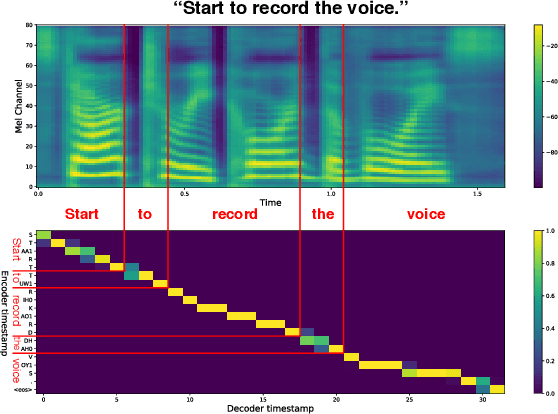
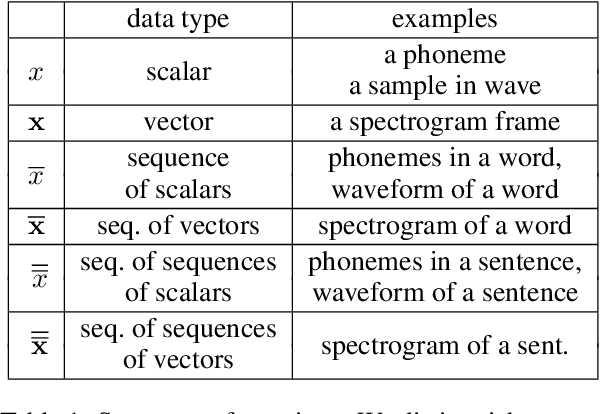
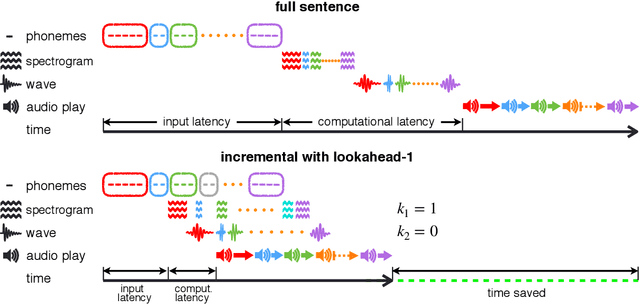
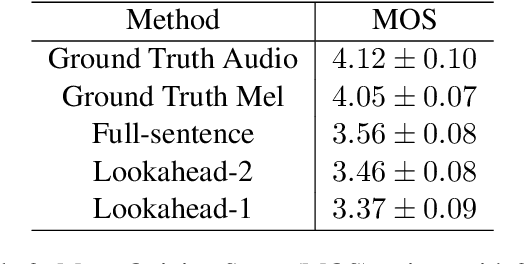
Text-to-speech synthesis (TTS) has witnessed rapid progress in recent years, where neural methods became capable of producing audio with near human-level naturalness. However, these efforts still suffer from two types of latencies: (a) the computational latency (synthesize time), which grows linearly with the sentence length even with parallel approaches, and (b) the input latency in scenarios where the input text is incrementally generated (such as in simultaneous translation, dialog generation, and assistive technologies). To reduce these latencies, we devise the first neural incremental TTS approach based on the recently proposed prefix-to-prefix framework. We synthesize speech in an online fashion, playing a segment of audio while generating the next, resulting in an O(1) rather than O(n) latency. Experiments on English TTS show that our approach achieves similar speech naturalness compared to full sentence methods, but only using a fraction of time and a constant (1 - 2 words) latency.