 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised Learning of Detailed 3D Face Reconstruction
Paper and Code

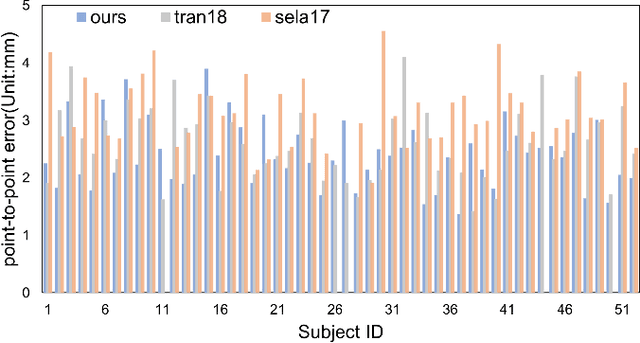
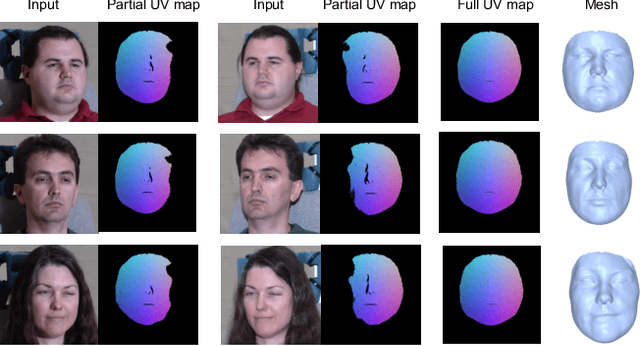

In this paper, we present an end-to-end learning framework for detailed 3D face reconstruction from a single image. Our approach uses a 3DMM-based coarse model and a displacement map in UV-space to represent a 3D face. Unlike previous work addressing the problem, our learning framework does not require supervision of surrogate ground-truth 3D models computed with traditional approaches. Instead, we utilize the input image itself as supervision during learning. In the first stage, we combine a photometric loss and a facial perceptual loss between the input face and the rendered face, to regress a 3DMM-based coarse model. In the second stage, both the input image and the regressed texture of the coarse model are unwrapped into UV-space, and then sent through an image-toimage translation network to predict a displacement map in UVspace. The displacement map and the coarse model are used to render a final detailed face, which again can be compared with the original input image to serve as a photometric loss for the second stage. The advantage of learning displacement map in UV-space is that face alignment can be explicitly done during the unwrapping, thus facial details are easier to learn from large amount of data. Extensive experiments demonstrate the superiority of the proposed method over previous work.