Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructural sparsification for Far-field Speaker Recognition with GNA
Paper and Code
Oct 25, 2019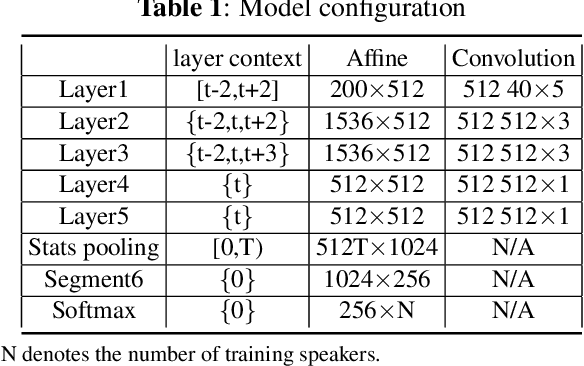
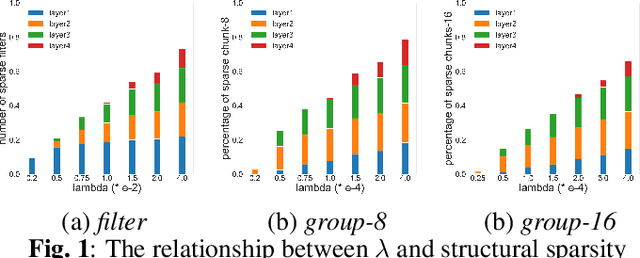
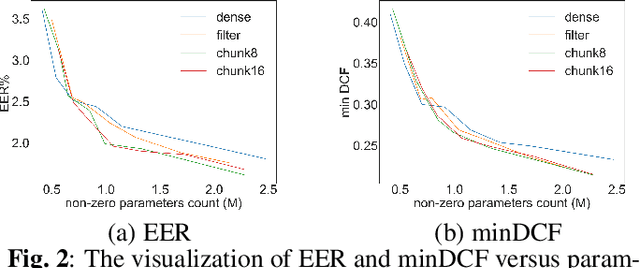
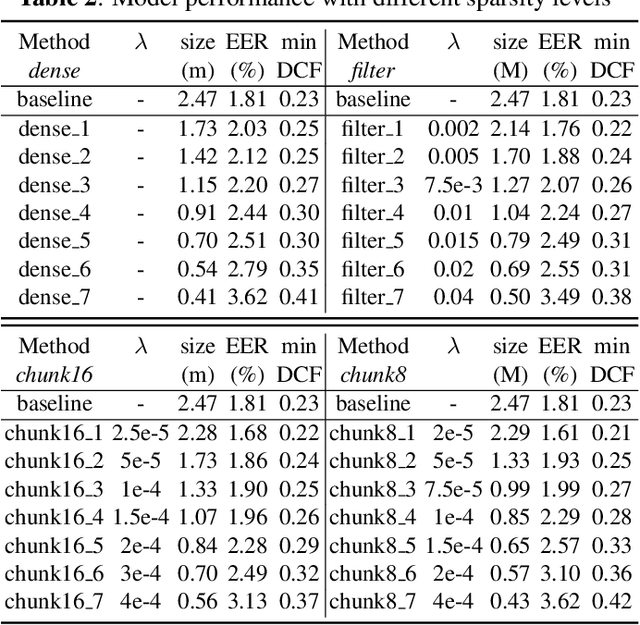
Recently, deep neural networks (DNN) have been widely used in speaker recognition area. In order to achieve fast response time and high accuracy, the requirements for hardware resources increase rapidly. However, as the speaker recognition application is often implemented on mobile devices, it is necessary to maintain a low computational cost while keeping high accuracy in far-field condition. In this paper, we apply structural sparsification on time-delay neural networks (TDNN) to remove redundant structures and accelerate the execution. On our targeted hardware, our model can remove 60% of parameters and only slightly increasing equal error rate (EER) by 0.18% while our structural sparse model can achieve more than 2x speedup.
* submitted to icassp2020
View paper on