 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPEC2: SPECtral SParsE CNN Accelerator on FPGAs
Paper and Code
Oct 16, 2019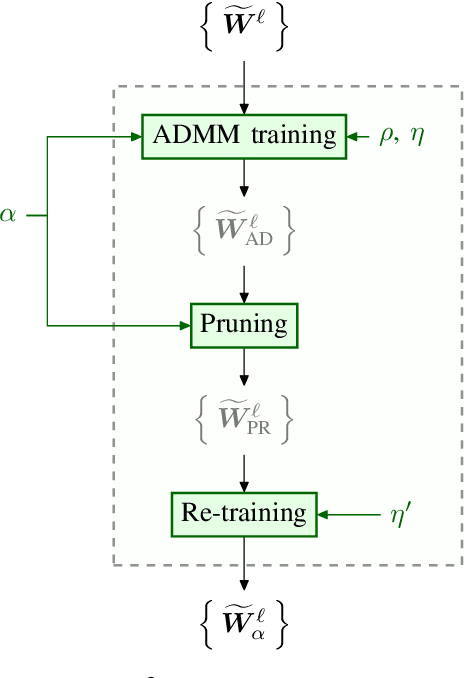
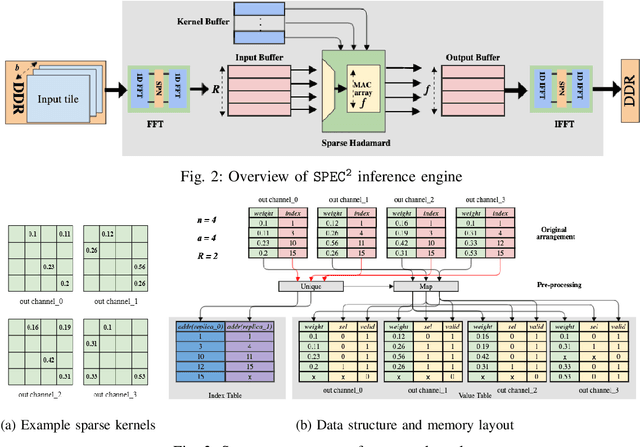

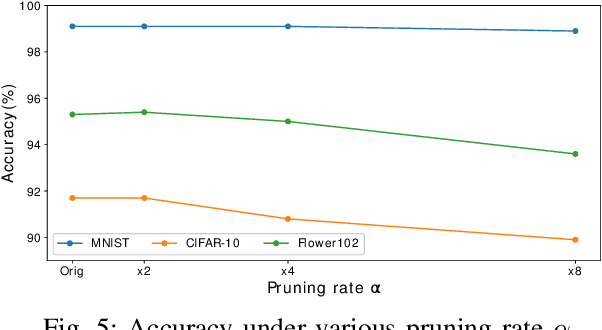
To accelerate inference of Convolutional Neural Networks (CNNs), various techniques have been proposed to reduce computation redundancy. Converting convolutional layers into frequency domain significantly reduces the computation complexity of the sliding window operations in space domain. On the other hand, weight pruning techniques address the redundancy in model parameters by converting dense convolutional kernels into sparse ones. To obtain high-throughput FPGA implementation, we propose SPEC2 -- the first work to prune and accelerate spectral CNNs. First, we propose a systematic pruning algorithm based on Alternative Direction Method of Multipliers (ADMM). The offline pruning iteratively sets the majority of spectral weights to zero, without using any handcrafted heuristics. Then, we design an optimized pipeline architecture on FPGA that has efficient random access into the sparse kernels and exploits various dimensions of parallelism in convolutional layers. Overall, SPEC2 achieves high inference throughput with extremely low computation complexity and negligible accuracy degradation. We demonstrate SPEC2 by pruning and implementing LeNet and VGG16 on the Xilinx Virtex platform. After pruning 75% of the spectral weights, SPEC2 achieves 0% accuracy loss for LeNet, and <1% accuracy loss for VGG16. The resulting accelerators achieve up to 24x higher throughput, compared with the state-of-the-art FPGA implementations for VGG16.