 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Zero-Inflated Quality Estimation Model For Automatic Speech Recognition System
Paper and Code
Oct 03, 2019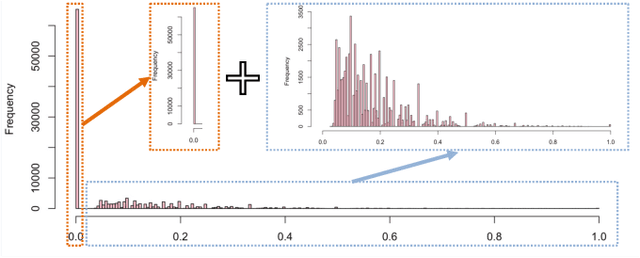

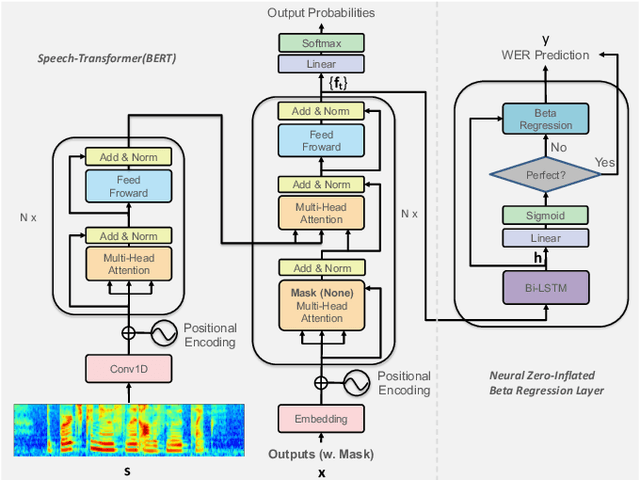

The performances of automatic speech recognition (ASR) systems are usually evaluated by the metric word error rate (WER) when the manually transcribed data are provided, which are, however, expensively available in the real scenario. In addition, the empirical distribution of WER for most ASR systems usually tends to put a significant mass near zero, making it difficult to simulate with a single continuous distribution. In order to address the two issues of ASR quality estimation (QE), we propose a novel neural zero-inflated model to predict the WER of the ASR result without transcripts. We design a neural zero-inflated beta regression on top of a bidirectional transformer language model conditional on speech features (speech-BERT). We adopt the pre-training strategy of token level mask language modeling for speech-BERT as well, and further fine-tune with our zero-inflated layer for the mixture of discrete and continuous outputs. The experimental results show that our approach achieves better performance on WER prediction in the metrics of Pearson and MAE, compared with most existed quality estimation algorithms for ASR or machine translation.