 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Layered Architecture for Active Perception: Image Classification using Deep Reinforcement Learning
Paper and Code
Sep 20, 2019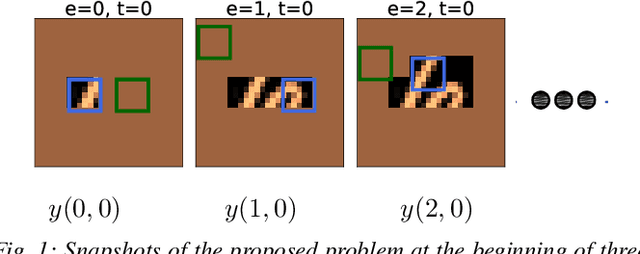
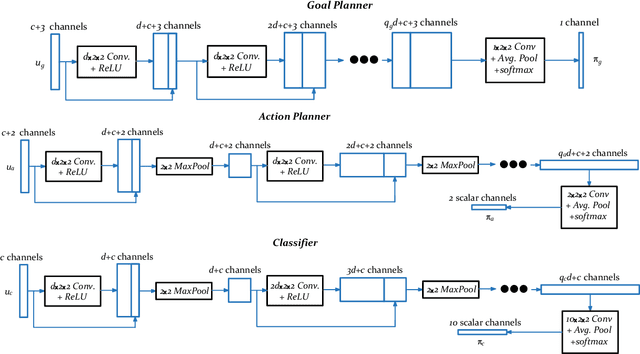

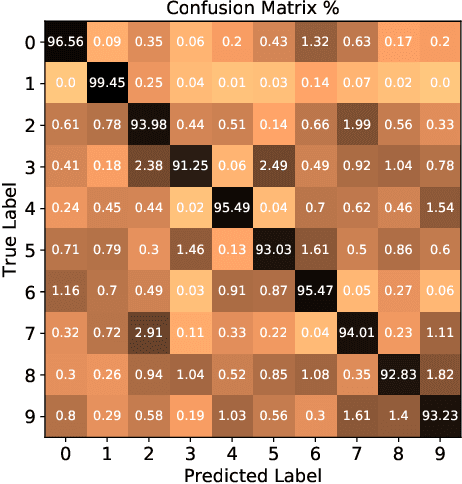
We propose a planning and perception mechanism for a robot (agent), that can only observe the underlying environment partially, in order to solve an image classification problem. A three-layer architecture is suggested that consists of a meta-layer that decides the intermediate goals, an action-layer that selects local actions as the agent navigates towards a goal, and a classification-layer that evaluates the reward and makes a prediction. We design and implement these layers using deep reinforcement learning. A generalized policy gradient algorithm is utilized to learn the parameters of these layers to maximize the expected reward. Our proposed methodology is tested on the MNIST dataset of handwritten digits, which provides us with a level of explainability while interpreting the agent's intermediate goals and course of action.