 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-trained Language Model for Biomedical Question Answering
Paper and Code
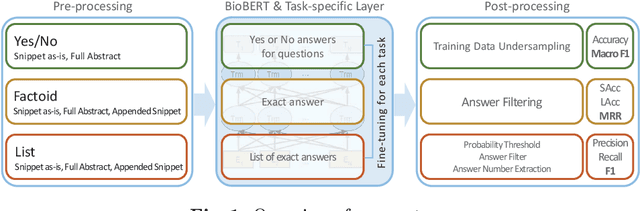
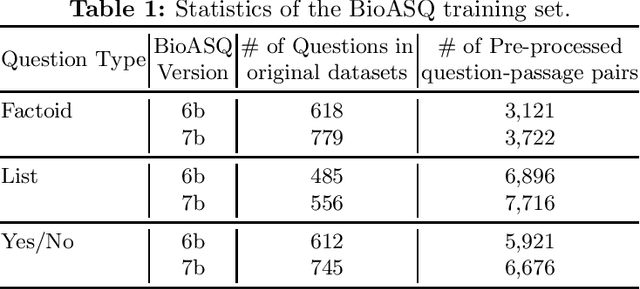
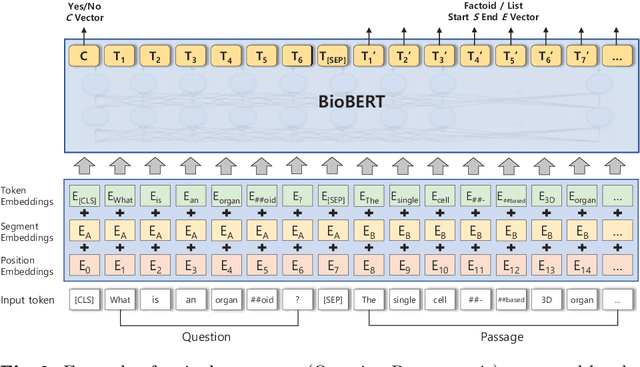
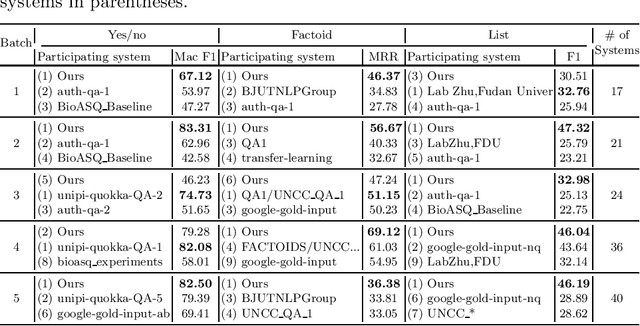
The recent success of question answering systems is largely attributed to pre-trained language models. However, as language models are mostly pre-trained on general domain corpora such as Wikipedia, they often have difficulty in understanding biomedical questions. In this paper, we investigate the performance of BioBERT, a pre-trained biomedical language model, in answering biomedical questions including factoid, list, and yes/no type questions. BioBERT uses almost the same structure across various question types and achieved the best performance in the 7th BioASQ Challenge (Task 7b, Phase B). BioBERT pre-trained on SQuAD or SQuAD 2.0 easily outperformed previous state-of-the-art models. BioBERT obtains the best performance when it uses the appropriate pre-/post-processing strategies for questions, passages, and answers.