 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Inference of Reward Machines and Policies for Reinforcement Learning
Paper and Code
Sep 12, 2019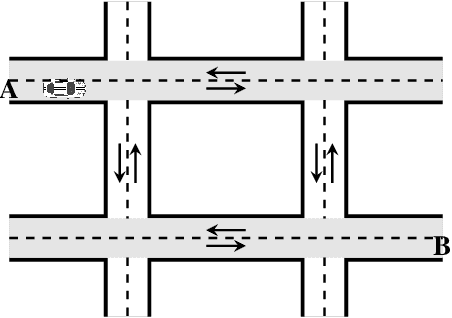

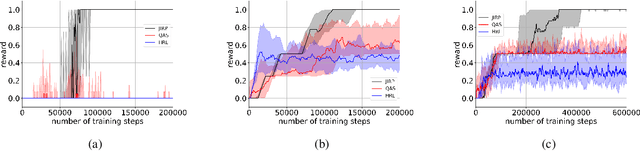
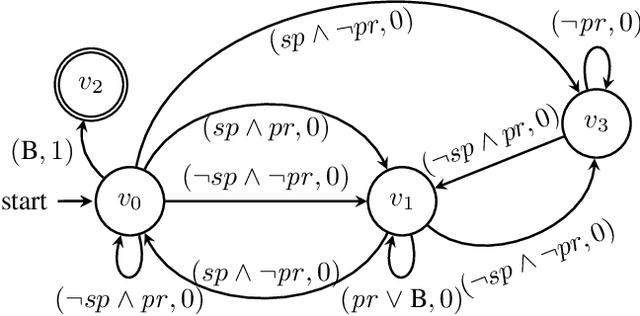
Incorporating high-level knowledge is an effective way to expedite reinforcement learning (RL), especially for complex tasks with sparse rewards. We investigate an RL problem where the high-level knowledge is in the form of reward machines, i.e., a type of Mealy machine that encodes the reward functions. We focus on a setting in which this knowledge is a priori not available to the learning agent. We develop an iterative algorithm that performs joint inference of reward machines and policies for RL (more specifically, q-learning). In each iteration, the algorithm maintains a hypothesis reward machine and a sample of RL episodes. It derives q-functions from the current hypothesis reward machine, and performs RL to update the q-functions. While performing RL, the algorithm updates the sample by adding RL episodes along which the obtained rewards are inconsistent with the rewards based on the current hypothesis reward machine. In the next iteration, the algorithm infers a new hypothesis reward machine from the updated sample. Based on an equivalence relationship we defined between states of reward machines, we transfer the q-functions between the hypothesis reward machines in consecutive iterations. We prove that the proposed algorithm converges almost surely to an optimal policy in the limit if a minimal reward machine can be inferred and the maximal length of each RL episode is sufficiently long. The experiments show that learning high-level knowledge in the form of reward machines can lead to fast convergence to optimal policies in RL, while standard RL methods such as q-learning and hierarchical RL methods fail to converge to optimal policies after a substantial number of training steps in many tasks.