 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Vector-valued Functions with Local Rademacher Complexity
Paper and Code
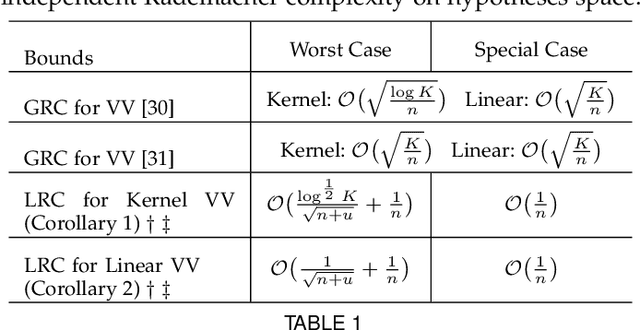
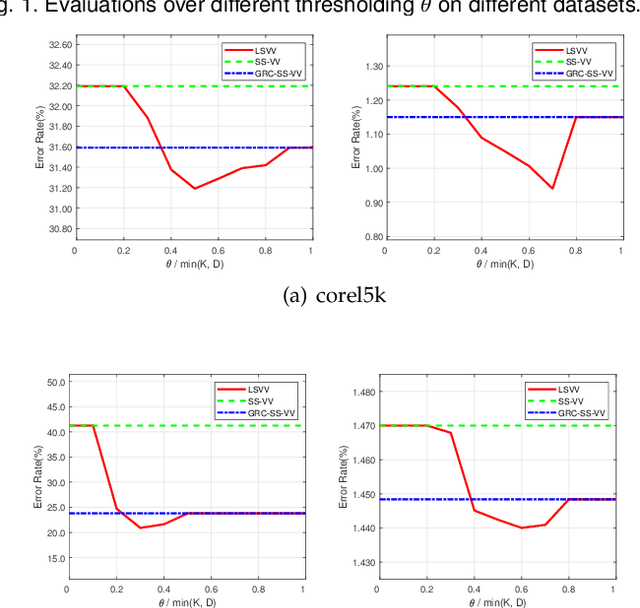

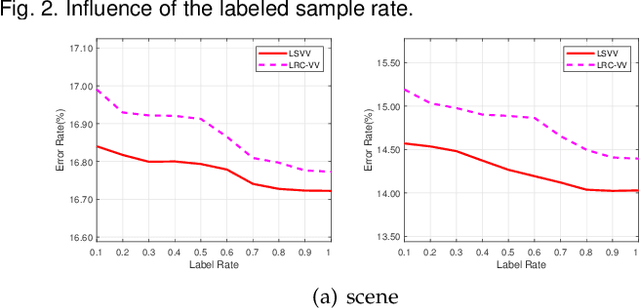
We consider a general family of problems of which the output space admits vector-valued structure, covering a broad family of important domains, e.g. multi-label learning and multi-class classification. By using local Rademacher complexity and unlabeled data, we derived novel data-dependent excess risk bounds for vector-valued functions in both linear space and kernel space. The proposed bounds are much sharper than existing bounds and can be applied into specific vector-valued tasks in terms of different hypotheses sets and loss functions. Theoretical analysis motivates us to devise a unified learning framework for vector-valued functions based which is solved by proximal gradient descent on the primal, achieving a much better tradeoff between accuracy and efficiency. Empirical results on several benchmark datasets show that the proposed algorithm outperforms compared methods significantly, which coincides with our theoretical analysis.