 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Hypernymy in Text-Rich Heterogeneous Information Network by Exploiting Context Granularity
Paper and Code
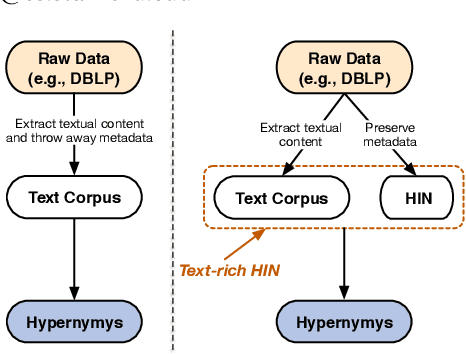

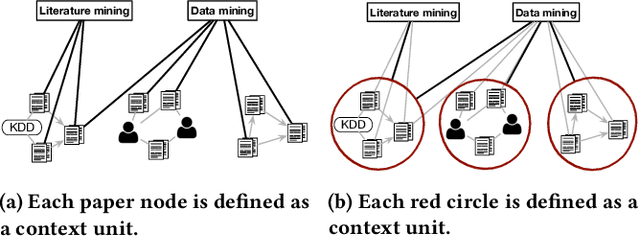

Text-rich heterogeneous information networks (text-rich HINs) are ubiquitous in real-world applications. Hypernymy, also known as is-a relation or subclass-of relation, lays in the core of many knowledge graphs and benefits many downstream applications. Existing methods of hypernymy discovery either leverage textual patterns to extract explicitly mentioned hypernym-hyponym pairs, or learn a distributional representation for each term of interest based its context. These approaches rely on statistical signals from the textual corpus, and their effectiveness would therefore be hindered when the signals from the corpus are not sufficient for all terms of interest. In this work, we propose to discover hypernymy in text-rich HINs, which can introduce additional high-quality signals. We develop a new framework, named HyperMine, that exploits multi-granular contexts and combines signals from both text and network without human labeled data. HyperMine extends the definition of context to the scenario of text-rich HIN. For example, we can define typed nodes and communities as contexts. These contexts encode signals of different granularities and we feed them into a hypernymy inference model. HyperMine learns this model using weak supervision acquired based on high-precision textual patterns. Extensive experiments on two large real-world datasets demonstrate the effectiveness of HyperMine and the utility of modeling context granularity. We further show a case study that a high-quality taxonomy can be generated solely based on the hypernymy discovered by HyperMine.