 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat You See is What You Get: Visual Pronoun Coreference Resolution in Dialogues
Paper and Code

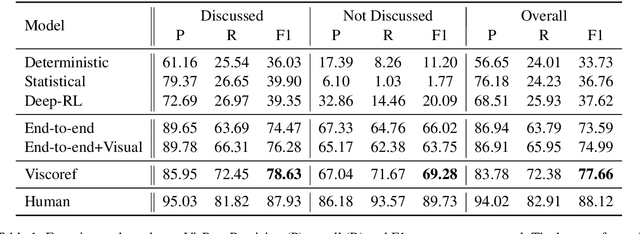
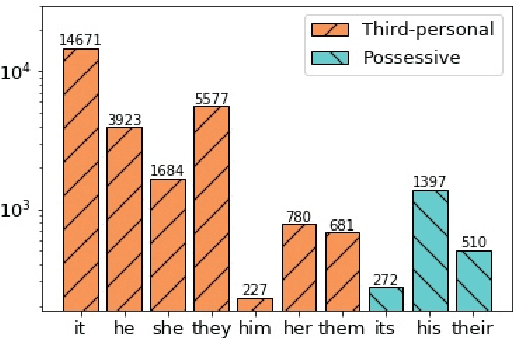
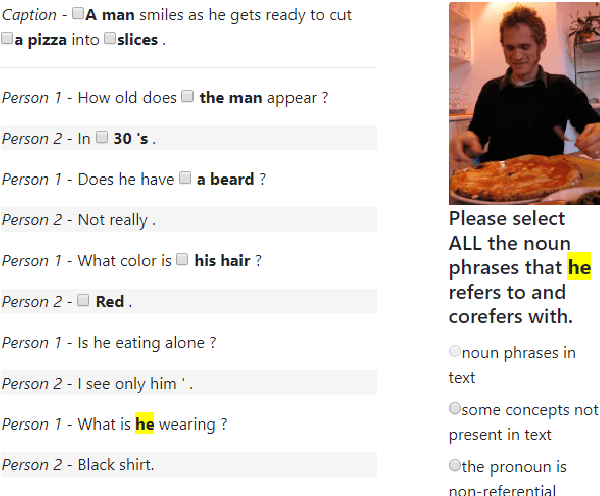
Grounding a pronoun to a visual object it refers to requires complex reasoning from various information sources, especially in conversational scenarios. For example, when people in a conversation talk about something all speakers can see, they often directly use pronouns (e.g., it) to refer to it without previous introduction. This fact brings a huge challenge for modern natural language understanding systems, particularly conventional context-based pronoun coreference models. To tackle this challenge, in this paper, we formally define the task of visual-aware pronoun coreference resolution (PCR) and introduce VisPro, a large-scale dialogue PCR dataset, to investigate whether and how the visual information can help resolve pronouns in dialogues. We then propose a novel visual-aware PCR model, VisCoref, for this task and conduct comprehensive experiments and case studies on our dataset. Results demonstrate the importance of the visual information in this PCR case and show the effectiveness of the proposed model.