 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting information from free text through unsupervised graph-based clustering: an application to patient incident records
Paper and Code
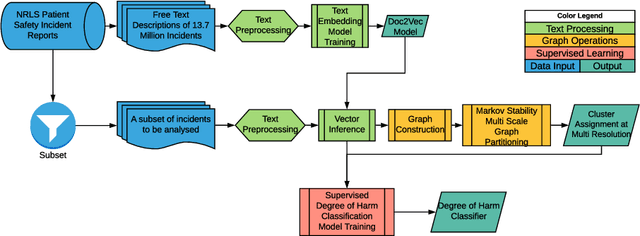
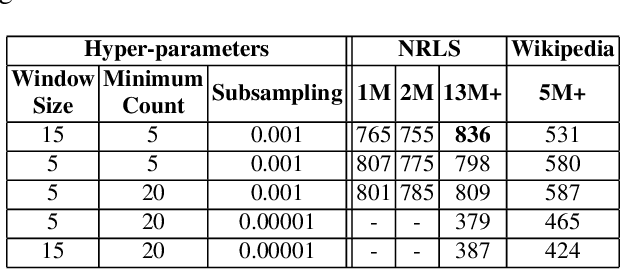
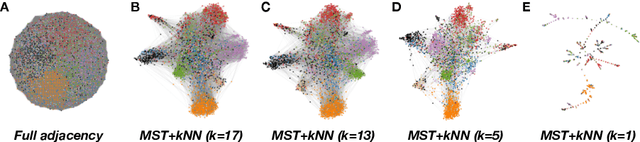
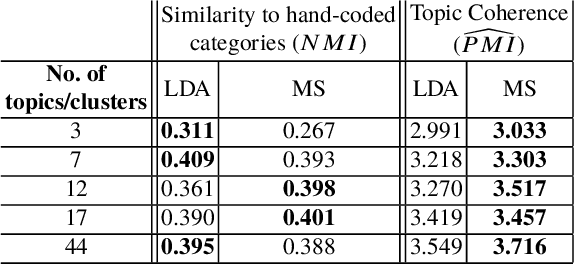
The large volume of text in electronic healthcare records often remains underused due to a lack of methodologies to extract interpretable content. Here we present an unsupervised framework for the analysis of free text that combines text-embedding with paragraph vectors and graph-theoretical multiscale community detection. We analyse text from a corpus of patient incident reports from the National Health Service in England to find content-based clusters of reports in an unsupervised manner and at different levels of resolution. Our unsupervised method extracts groups with high intrinsic textual consistency and compares well against categories hand-coded by healthcare personnel. We also show how to use our content-driven clusters to improve the supervised prediction of the degree of harm of the incident based on the text of the report. Finally, we discuss future directions to monitor reports over time, and to detect emerging trends outside pre-existing categories.