 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeICE-NODE: Integration of Clinical Embeddings with Neural Ordinary Differential Equations
Jul 06, 2022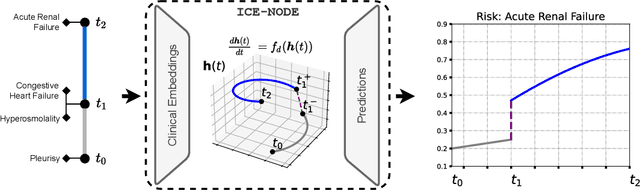
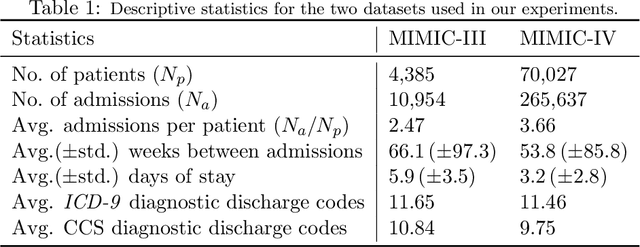
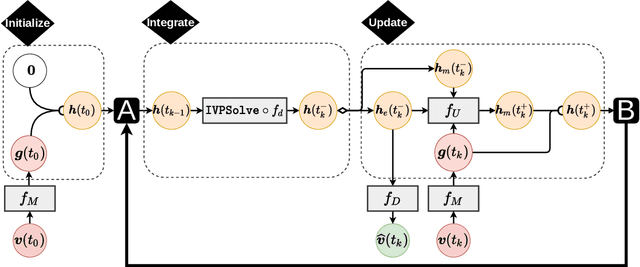
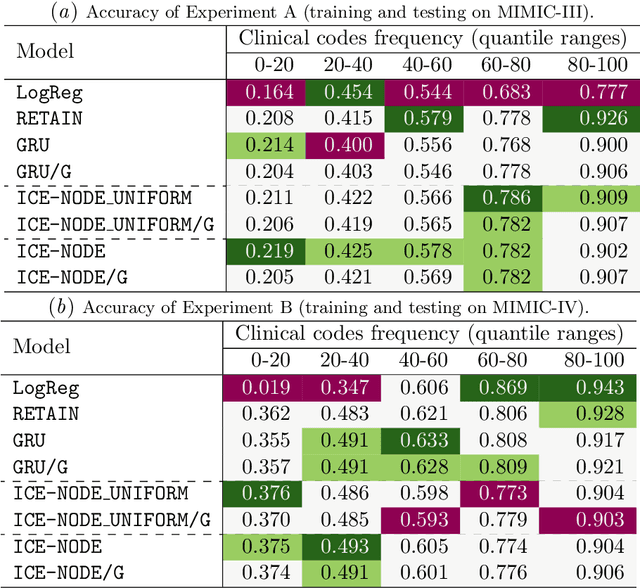
Early diagnosis of disease can result in improved health outcomes, such as higher survival rates and lower treatment costs. With the massive amount of information in electronic health records (EHRs), there is great potential to use machine learning (ML) methods to model disease progression aimed at early prediction of disease onset and other outcomes. In this work, we employ recent innovations in neural ODEs to harness the full temporal information of EHRs. We propose ICE-NODE (Integration of Clinical Embeddings with Neural Ordinary Differential Equations), an architecture that temporally integrates embeddings of clinical codes and neural ODEs to learn and predict patient trajectories in EHRs. We apply our method to the publicly available MIMIC-III and MIMIC-IV datasets, reporting improved prediction results compared to state-of-the-art methods, specifically for clinical codes that are not frequently observed in EHRs. We also show that ICE-NODE is more competent at predicting certain medical conditions, like acute renal failure and pulmonary heart disease, and is also able to produce patient risk trajectories over time that can be exploited for further predictions.
Extracting information from free text through unsupervised graph-based clustering: an application to patient incident records
Aug 31, 2019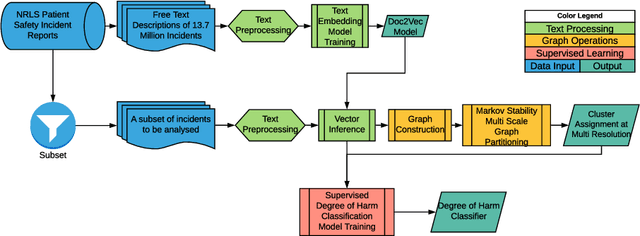
The large volume of text in electronic healthcare records often remains underused due to a lack of methodologies to extract interpretable content. Here we present an unsupervised framework for the analysis of free text that combines text-embedding with paragraph vectors and graph-theoretical multiscale community detection. We analyse text from a corpus of patient incident reports from the National Health Service in England to find content-based clusters of reports in an unsupervised manner and at different levels of resolution. Our unsupervised method extracts groups with high intrinsic textual consistency and compares well against categories hand-coded by healthcare personnel. We also show how to use our content-driven clusters to improve the supervised prediction of the degree of harm of the incident based on the text of the report. Finally, we discuss future directions to monitor reports over time, and to detect emerging trends outside pre-existing categories.
From Free Text to Clusters of Content in Health Records: An Unsupervised Graph Partitioning Approach
Nov 14, 2018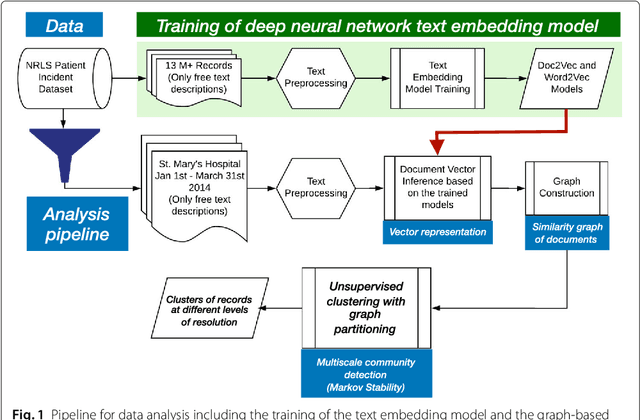
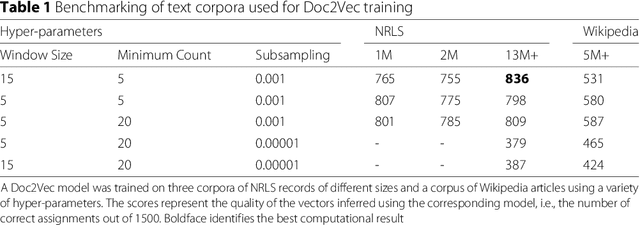
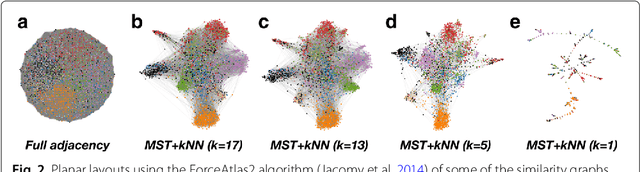
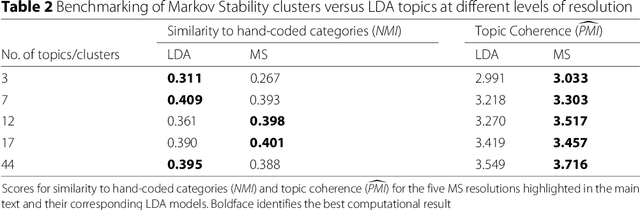
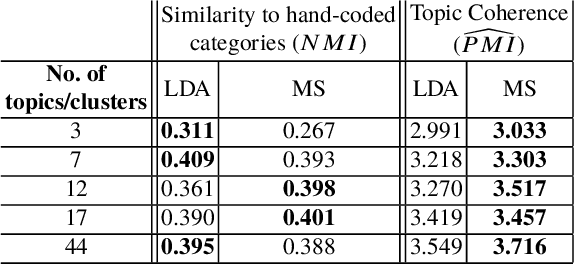
Electronic Healthcare records contain large volumes of unstructured data in different forms. Free text constitutes a large portion of such data, yet this source of richly detailed information often remains under-used in practice because of a lack of suitable methodologies to extract interpretable content in a timely manner. Here we apply network-theoretical tools to the analysis of free text in Hospital Patient Incident reports in the English National Health Service, to find clusters of reports in an unsupervised manner and at different levels of resolution based directly on the free text descriptions contained within them. To do so, we combine recently developed deep neural network text-embedding methodologies based on paragraph vectors with multi-scale Markov Stability community detection applied to a similarity graph of documents obtained from sparsified text vector similarities. We showcase the approach with the analysis of incident reports submitted in Imperial College Healthcare NHS Trust, London. The multiscale community structure reveals levels of meaning with different resolution in the topics of the dataset, as shown by relevant descriptive terms extracted from the groups of records, as well as by comparing a posteriori against hand-coded categories assigned by healthcare personnel. Our content communities exhibit good correspondence with well-defined hand-coded categories, yet our results also provide further medical detail in certain areas as well as revealing complementary descriptors of incidents beyond the external classification. We also discuss how the method can be used to monitor reports over time and across different healthcare providers, and to detect emerging trends that fall outside of pre-existing categories.
From Text to Topics in Healthcare Records: An Unsupervised Graph Partitioning Methodology
Jul 07, 2018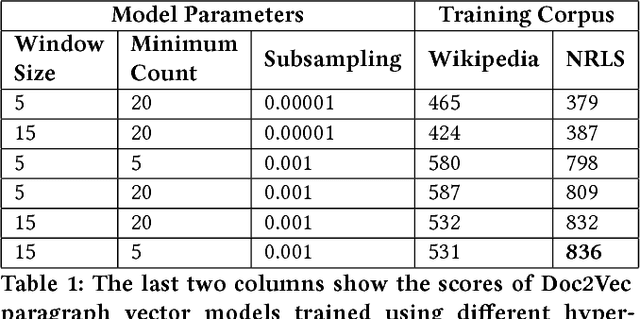
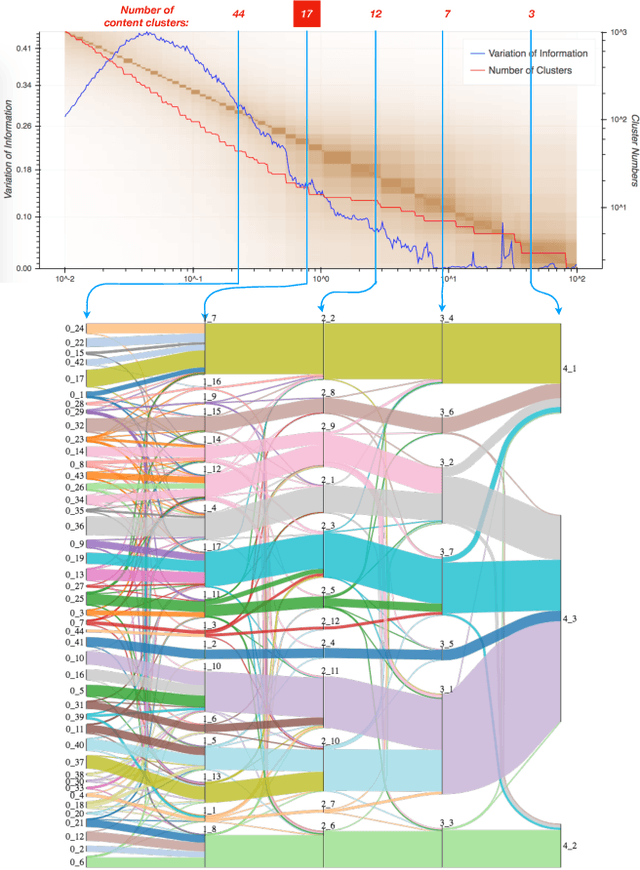
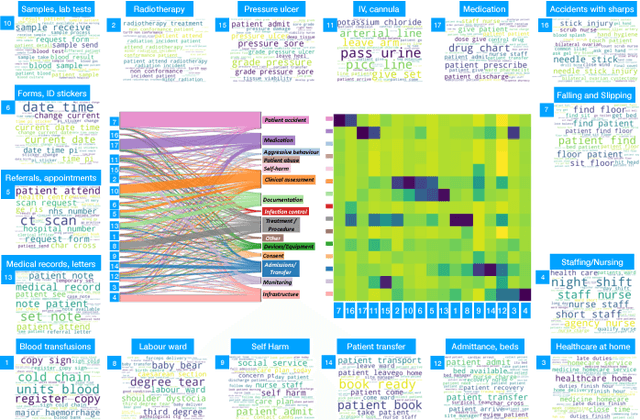
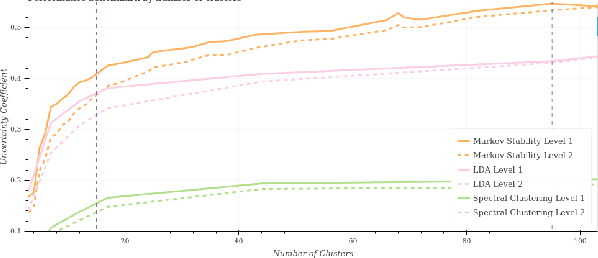
Electronic Healthcare Records contain large volumes of unstructured data, including extensive free text. Yet this source of detailed information often remains under-used because of a lack of methodologies to extract interpretable content in a timely manner. Here we apply network-theoretical tools to analyse free text in Hospital Patient Incident reports from the National Health Service, to find clusters of documents with similar content in an unsupervised manner at different levels of resolution. We combine deep neural network paragraph vector text-embedding with multiscale Markov Stability community detection applied to a sparsified similarity graph of document vectors, and showcase the approach on incident reports from Imperial College Healthcare NHS Trust, London. The multiscale community structure reveals different levels of meaning in the topics of the dataset, as shown by descriptive terms extracted from the clusters of records. We also compare a posteriori against hand-coded categories assigned by healthcare personnel, and show that our approach outperforms LDA-based models. Our content clusters exhibit good correspondence with two levels of hand-coded categories, yet they also provide further medical detail in certain areas and reveal complementary descriptors of incidents beyond the external classification taxonomy.