 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGraph-based Topic Extraction from Vector Embeddings of Text Documents: Application to a Corpus of News Articles
Oct 28, 2020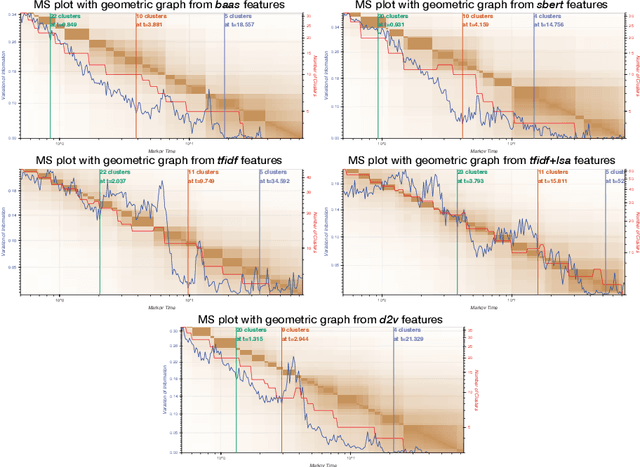
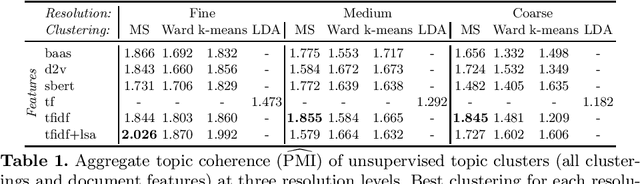
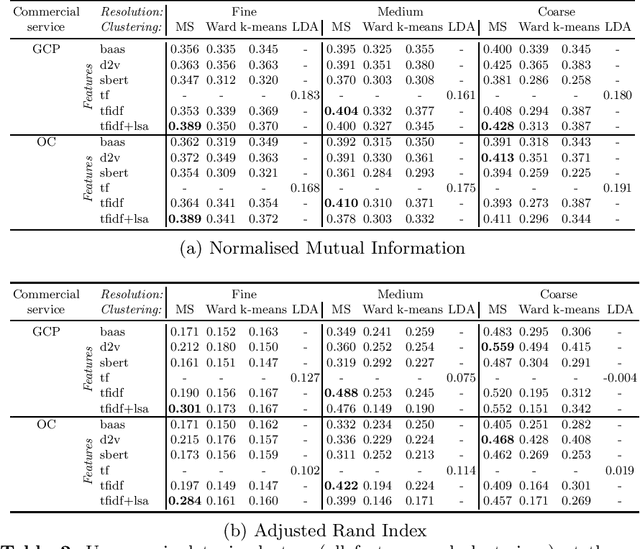
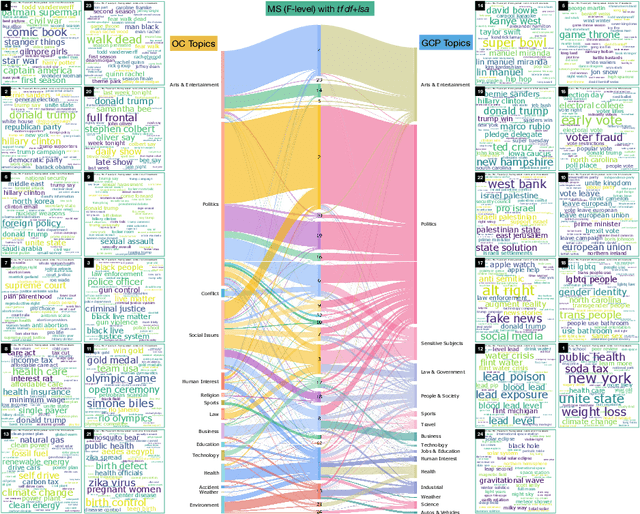
Production of news content is growing at an astonishing rate. To help manage and monitor the sheer amount of text, there is an increasing need to develop efficient methods that can provide insights into emerging content areas, and stratify unstructured corpora of text into `topics' that stem intrinsically from content similarity. Here we present an unsupervised framework that brings together powerful vector embeddings from natural language processing with tools from multiscale graph partitioning that can reveal natural partitions at different resolutions without making a priori assumptions about the number of clusters in the corpus. We show the advantages of graph-based clustering through end-to-end comparisons with other popular clustering and topic modelling methods, and also evaluate different text vector embeddings, from classic Bag-of-Words to Doc2Vec to the recent transformers based model Bert. This comparative work is showcased through an analysis of a corpus of US news coverage during the presidential election year of 2016.
Extracting information from free text through unsupervised graph-based clustering: an application to patient incident records
Aug 31, 2019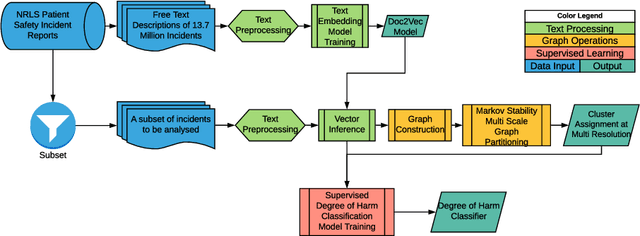
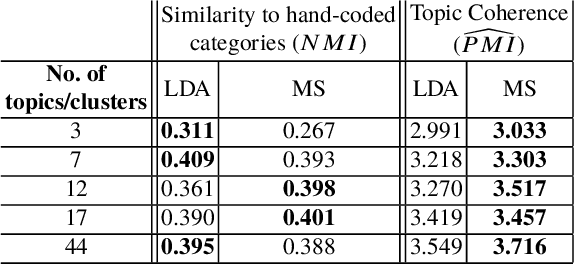
The large volume of text in electronic healthcare records often remains underused due to a lack of methodologies to extract interpretable content. Here we present an unsupervised framework for the analysis of free text that combines text-embedding with paragraph vectors and graph-theoretical multiscale community detection. We analyse text from a corpus of patient incident reports from the National Health Service in England to find content-based clusters of reports in an unsupervised manner and at different levels of resolution. Our unsupervised method extracts groups with high intrinsic textual consistency and compares well against categories hand-coded by healthcare personnel. We also show how to use our content-driven clusters to improve the supervised prediction of the degree of harm of the incident based on the text of the report. Finally, we discuss future directions to monitor reports over time, and to detect emerging trends outside pre-existing categories.
From Free Text to Clusters of Content in Health Records: An Unsupervised Graph Partitioning Approach
Nov 14, 2018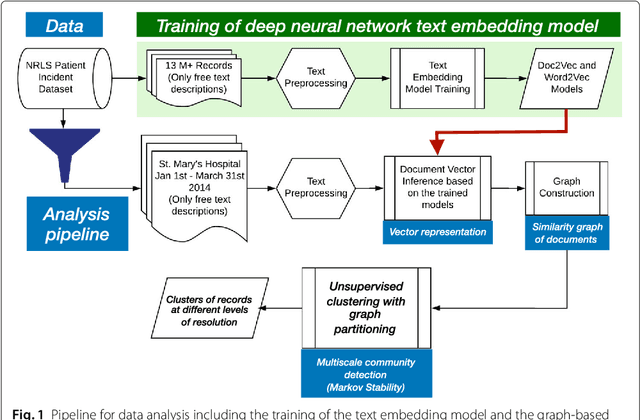
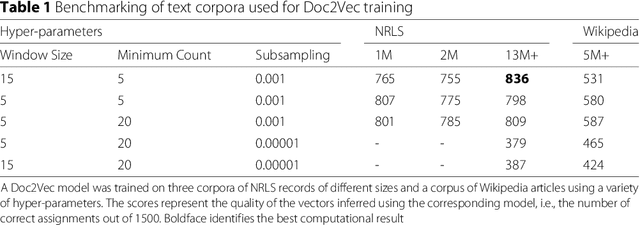
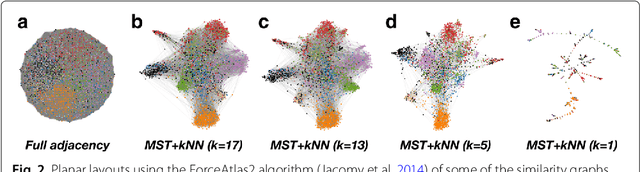
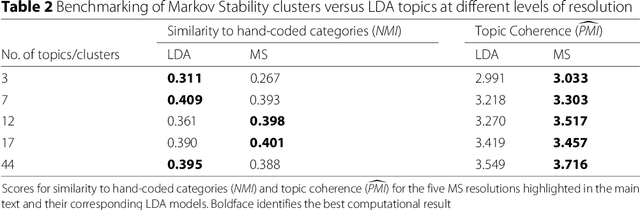
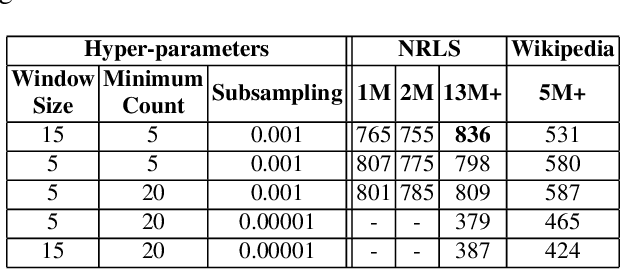
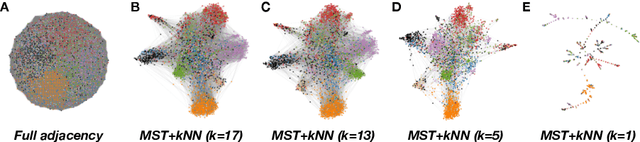
Electronic Healthcare records contain large volumes of unstructured data in different forms. Free text constitutes a large portion of such data, yet this source of richly detailed information often remains under-used in practice because of a lack of suitable methodologies to extract interpretable content in a timely manner. Here we apply network-theoretical tools to the analysis of free text in Hospital Patient Incident reports in the English National Health Service, to find clusters of reports in an unsupervised manner and at different levels of resolution based directly on the free text descriptions contained within them. To do so, we combine recently developed deep neural network text-embedding methodologies based on paragraph vectors with multi-scale Markov Stability community detection applied to a similarity graph of documents obtained from sparsified text vector similarities. We showcase the approach with the analysis of incident reports submitted in Imperial College Healthcare NHS Trust, London. The multiscale community structure reveals levels of meaning with different resolution in the topics of the dataset, as shown by relevant descriptive terms extracted from the groups of records, as well as by comparing a posteriori against hand-coded categories assigned by healthcare personnel. Our content communities exhibit good correspondence with well-defined hand-coded categories, yet our results also provide further medical detail in certain areas as well as revealing complementary descriptors of incidents beyond the external classification. We also discuss how the method can be used to monitor reports over time and across different healthcare providers, and to detect emerging trends that fall outside of pre-existing categories.
Content-driven, unsupervised clustering of news articles through multiscale graph partitioning
Aug 03, 2018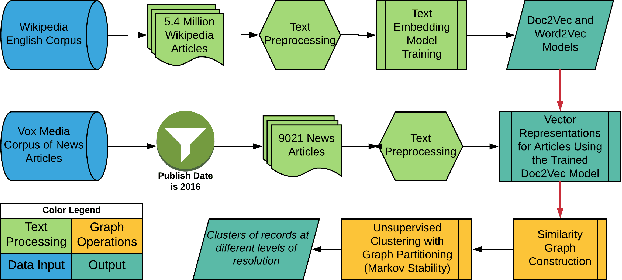
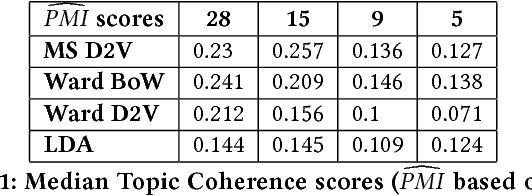
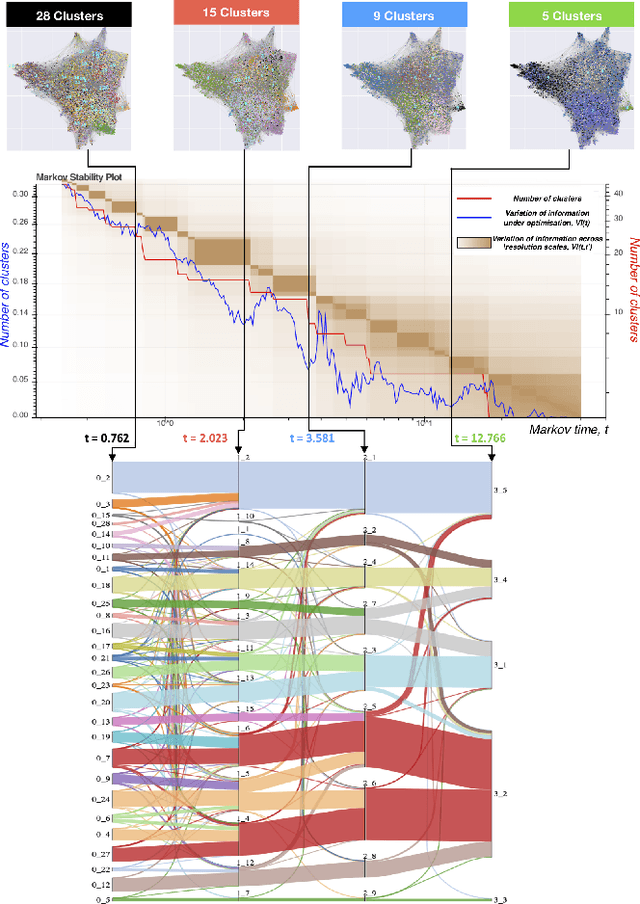
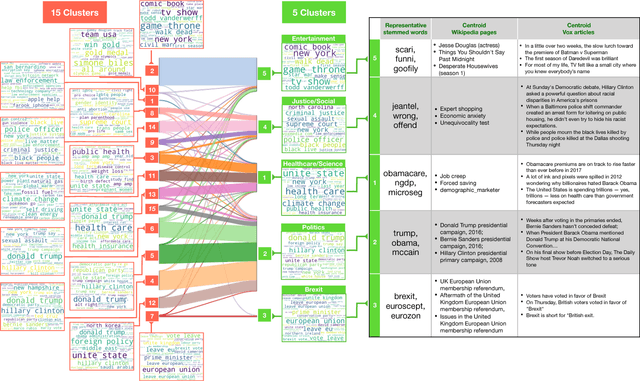
The explosion in the amount of news and journalistic content being generated across the globe, coupled with extended and instantaneous access to information through online media, makes it difficult and time-consuming to monitor news developments and opinion formation in real time. There is an increasing need for tools that can pre-process, analyse and classify raw text to extract interpretable content; specifically, identifying topics and content-driven groupings of articles. We present here such a methodology that brings together powerful vector embeddings from Natural Language Processing with tools from Graph Theory that exploit diffusive dynamics on graphs to reveal natural partitions across scales. Our framework uses a recent deep neural network text analysis methodology (Doc2vec) to represent text in vector form and then applies a multi-scale community detection method (Markov Stability) to partition a similarity graph of document vectors. The method allows us to obtain clusters of documents with similar content, at different levels of resolution, in an unsupervised manner. We showcase our approach with the analysis of a corpus of 9,000 news articles published by Vox Media over one year. Our results show consistent groupings of documents according to content without a priori assumptions about the number or type of clusters to be found. The multilevel clustering reveals a quasi-hierarchy of topics and subtopics with increased intelligibility and improved topic coherence as compared to external taxonomy services and standard topic detection methods.
From Text to Topics in Healthcare Records: An Unsupervised Graph Partitioning Methodology
Jul 07, 2018
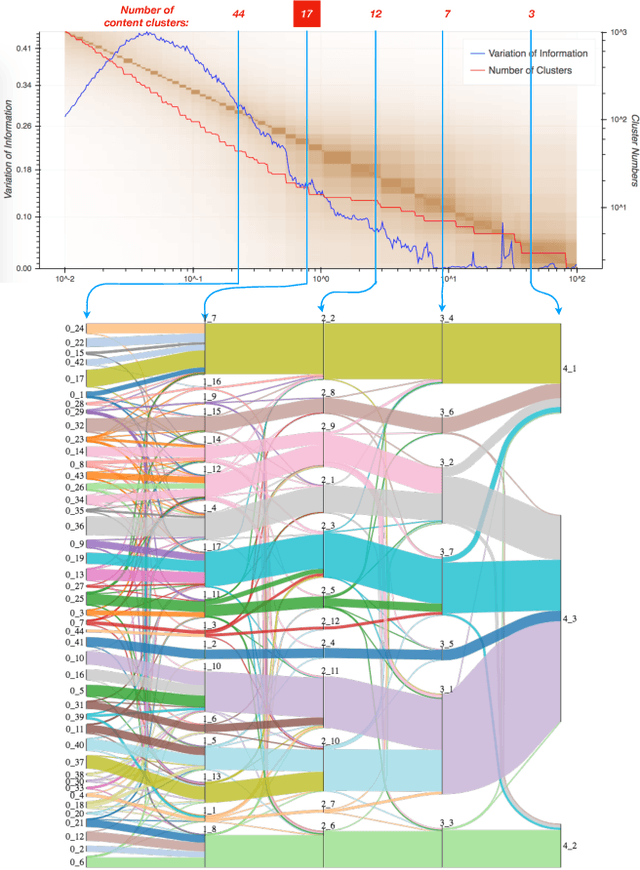
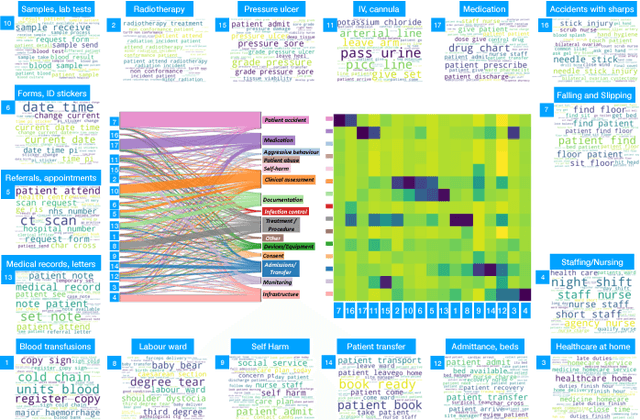
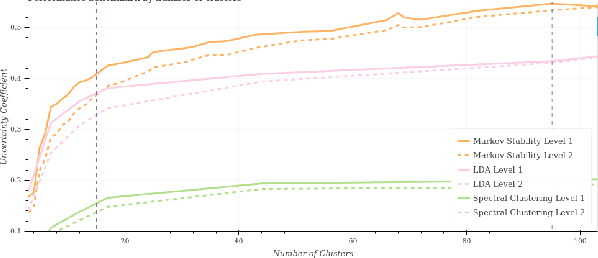
Electronic Healthcare Records contain large volumes of unstructured data, including extensive free text. Yet this source of detailed information often remains under-used because of a lack of methodologies to extract interpretable content in a timely manner. Here we apply network-theoretical tools to analyse free text in Hospital Patient Incident reports from the National Health Service, to find clusters of documents with similar content in an unsupervised manner at different levels of resolution. We combine deep neural network paragraph vector text-embedding with multiscale Markov Stability community detection applied to a sparsified similarity graph of document vectors, and showcase the approach on incident reports from Imperial College Healthcare NHS Trust, London. The multiscale community structure reveals different levels of meaning in the topics of the dataset, as shown by descriptive terms extracted from the clusters of records. We also compare a posteriori against hand-coded categories assigned by healthcare personnel, and show that our approach outperforms LDA-based models. Our content clusters exhibit good correspondence with two levels of hand-coded categories, yet they also provide further medical detail in certain areas and reveal complementary descriptors of incidents beyond the external classification taxonomy.