 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Resource Name Tagging Learned with Weakly Labeled Data
Paper and Code
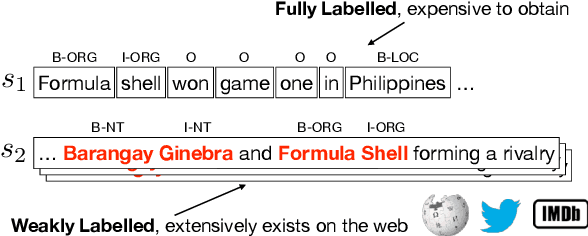
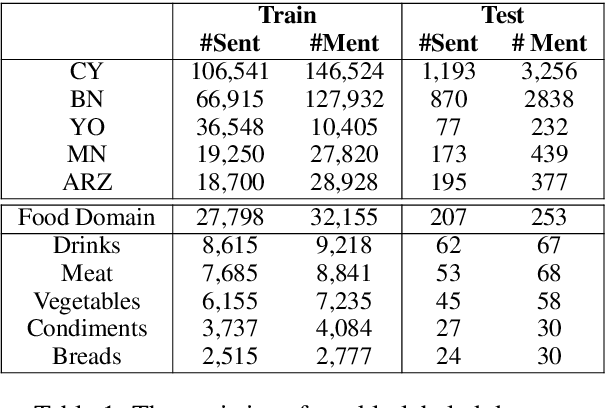
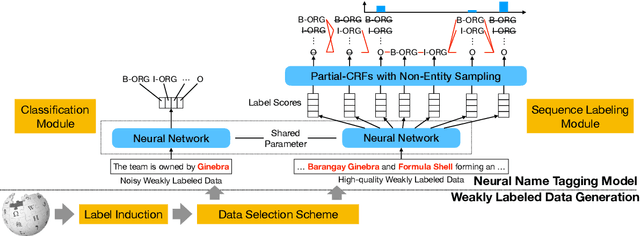

Name tagging in low-resource languages or domains suffers from inadequate training data. Existing work heavily relies on additional information, while leaving those noisy annotations unexplored that extensively exist on the web. In this paper, we propose a novel neural model for name tagging solely based on weakly labeled (WL) data, so that it can be applied in any low-resource settings. To take the best advantage of all WL sentences, we split them into high-quality and noisy portions for two modules, respectively: (1) a classification module focusing on the large portion of noisy data can efficiently and robustly pretrain the tag classifier by capturing textual context semantics; and (2) a costly sequence labeling module focusing on high-quality data utilizes Partial-CRFs with non-entity sampling to achieve global optimum. Two modules are combined via shared parameters. Extensive experiments involving five low-resource languages and fine-grained food domain demonstrate our superior performance (6% and 7.8% F1 gains on average) as well as efficiency.