 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbarrassingly Simple Binary Representation Learning
Paper and Code
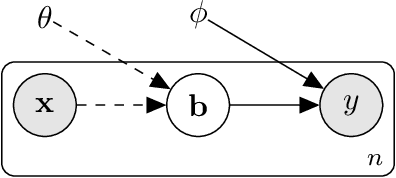

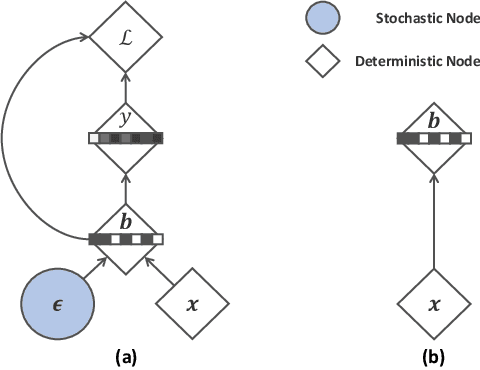
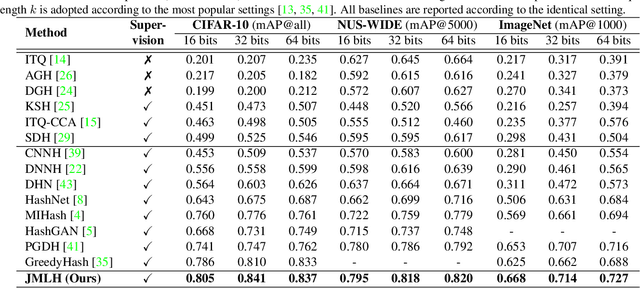
Recent binary representation learning models usually require sophisticated binary optimization, similarity measure or even generative models as auxiliaries. However, one may wonder whether these non-trivial components are needed to formulate practical and effective hashing models. In this paper, we answer the above question by proposing an embarrassingly simple approach to binary representation learning. With a simple classification objective, our model only incorporates two additional fully-connected layers onto the top of an arbitrary backbone network, whilst complying with the binary constraints during training. The proposed model lower-bounds the Information Bottleneck (IB) between data samples and their semantics, and can be related to many recent `learning to hash' paradigms. We show that, when properly designed, even such a simple network can generate effective binary codes, by fully exploring data semantics without any held-out alternating updating steps or auxiliary models. Experiments are conducted on conventional large-scale benchmarks, i.e., CIFAR-10, NUS-WIDE, and ImageNet, where the proposed simple model outperforms the state-of-the-art methods.