 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Embedding Gate for Attention-Based Scene Text Recognition
Paper and Code
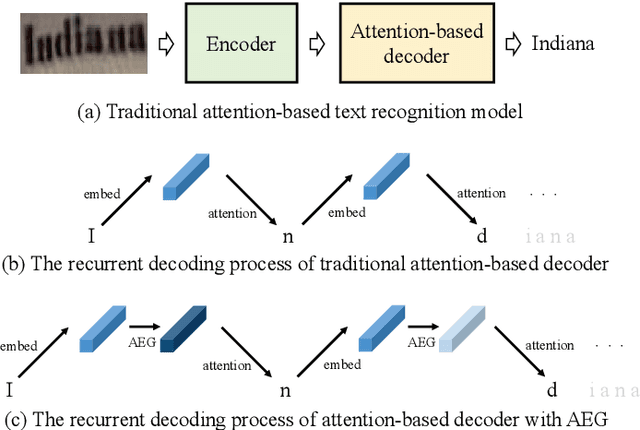
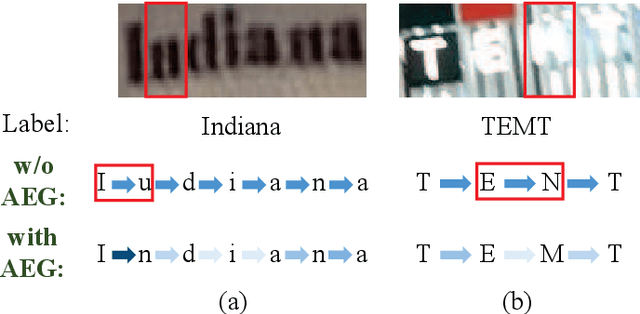
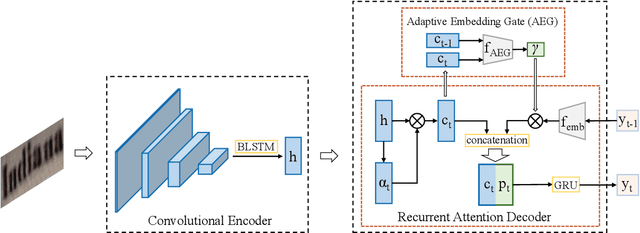

Scene text recognition has attracted particular research interest because it is a very challenging problem and has various applications. The most cutting-edge methods are attentional encoder-decoder frameworks that learn the alignment between the input image and output sequences. In particular, the decoder recurrently outputs predictions, using the prediction of the previous step as a guidance for every time step. In this study, we point out that the inappropriate use of previous predictions in existing attention mechanisms restricts the recognition performance and brings instability. To handle this problem, we propose a novel module, namely adaptive embedding gate(AEG). The proposed AEG focuses on introducing high-order character language models to attention mechanism by controlling the information transmission between adjacent characters. AEG is a flexible module and can be easily integrated into the state-of-the-art attentional methods. We evaluate its effectiveness as well as robustness on a number of standard benchmarks, including the IIIT$5$K, SVT, SVT-P, CUTE$80$, and ICDAR datasets. Experimental results demonstrate that AEG can significantly boost recognition performance and bring better robustness.