 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Seeded Sequence Growing for Weakly-Supervised Temporal Action Localization
Paper and Code
Aug 07, 2019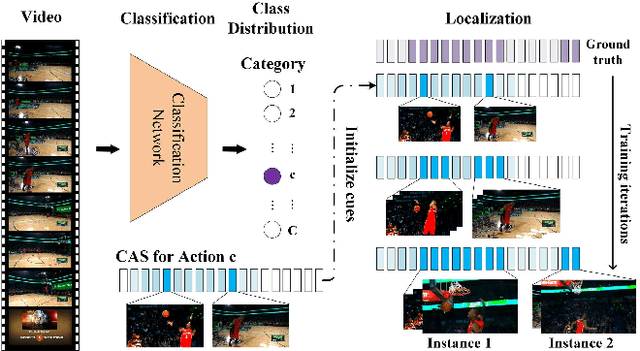
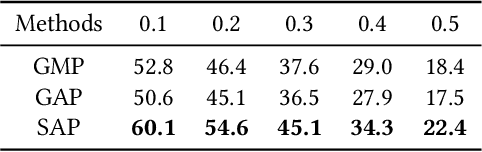
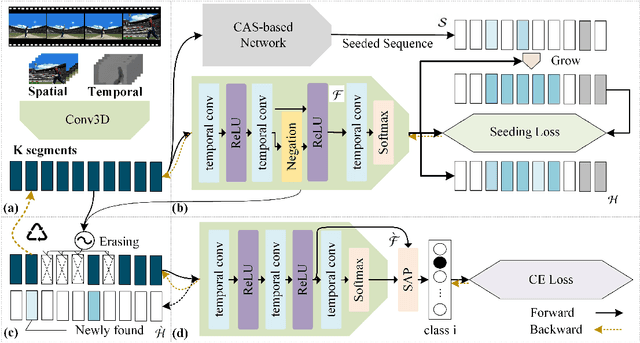
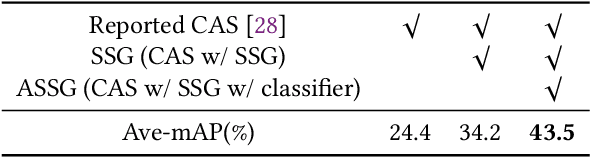
Temporal action localization is an important yet challenging research topic due to its various applications. Since the frame-level or segment-level annotations of untrimmed videos require amounts of labor expenditure, studies on the weakly-supervised action detection have been springing up. However, most of existing frameworks rely on Class Activation Sequence (CAS) to localize actions by minimizing the video-level classification loss, which exploits the most discriminative parts of actions but ignores the minor regions. In this paper, we propose a novel weakly-supervised framework by adversarial learning of two modules for eliminating such demerits. Specifically, the first module is designed as a well-designed Seeded Sequence Growing (SSG) Network for progressively extending seed regions (namely the highly reliable regions initialized by a CAS-based framework) to their expected boundaries. The second module is a specific classifier for mining trivial or incomplete action regions, which is trained on the shared features after erasing the seeded regions activated by SSG. In this way, a whole network composed of these two modules can be trained in an adversarial manner. The goal of the adversary is to mine features that are difficult for the action classifier. That is, erasion from SSG will force the classifier to discover minor or even new action regions on the input feature sequence, and the classifier will drive the seeds to grow, alternately. At last, we could obtain the action locations and categories from the well-trained SSG and the classifier. Extensive experiments on two public benchmarks THUMOS'14 and ActivityNet1.3 demonstrate the impressive performance of our proposed method compared with the state-of-the-arts.