 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Virtual Garment Modeling from RGB Images
Paper and Code
Jul 31, 2019

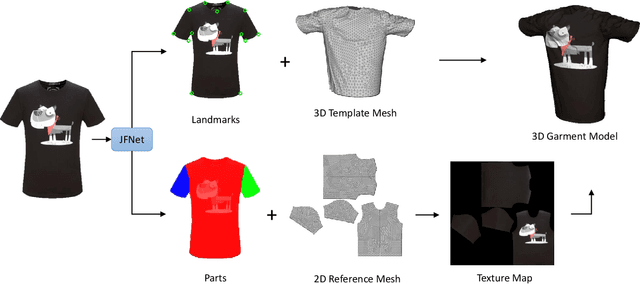

We present a novel approach that constructs 3D virtual garment models from photos. Unlike previous methods that require photos of a garment on a human model or a mannequin, our approach can work with various states of the garment: on a model, on a mannequin, or on a flat surface. To construct a complete 3D virtual model, our approach only requires two images as input, one front view and one back view. We first apply a multi-task learning network called JFNet that jointly predicts fashion landmarks and parses a garment image into semantic parts. The predicted landmarks are used for estimating sizing information of the garment. Then, a template garment mesh is deformed based on the sizing information to generate the final 3D model. The semantic parts are utilized for extracting color textures from input images. The results of our approach can be used in various Virtual Reality and Mixed Reality applications.