 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeformable Filter Convolution for Point Cloud Reasoning
Paper and Code
Jul 30, 2019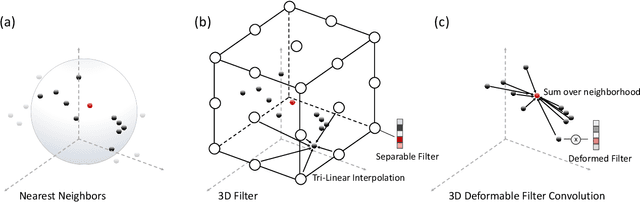
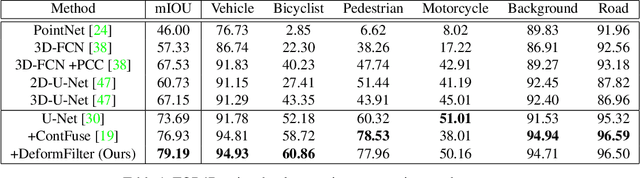
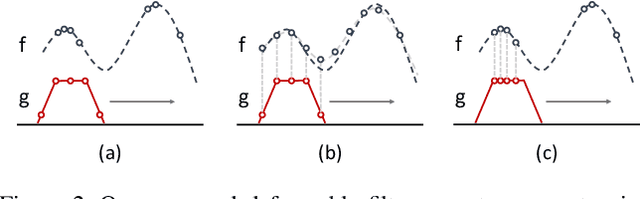
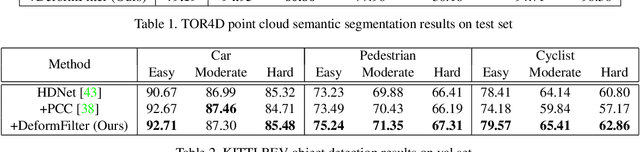
Point clouds are the native output of many real-world 3D sensors. To borrow the success of 2D convolutional network architectures, a majority of popular 3D perception models voxelize the points, which can result in a loss of local geometric details that cannot be recovered. In this paper, we propose a novel learnable convolution layer for processing 3D point cloud data directly. Instead of discretizing points into fixed voxels, we deform our learnable 3D filters to match with the point cloud shape. We propose to combine voxelized backbone networks with our deformable filter layer at 1) the network input stream and 2) the output prediction layers to enhance point level reasoning. We obtain state-of-the-art results on LiDAR semantic segmentation and producing a significant gain in performance on LiDAR object detection.