 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing 3D Convolutional Neural Networks to Learn Spatiotemporal Features for Automatic Surgical Gesture Recognition in Video
Paper and Code
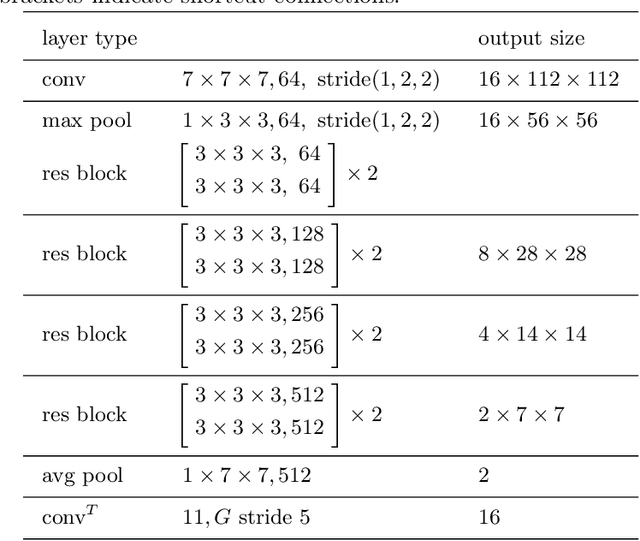


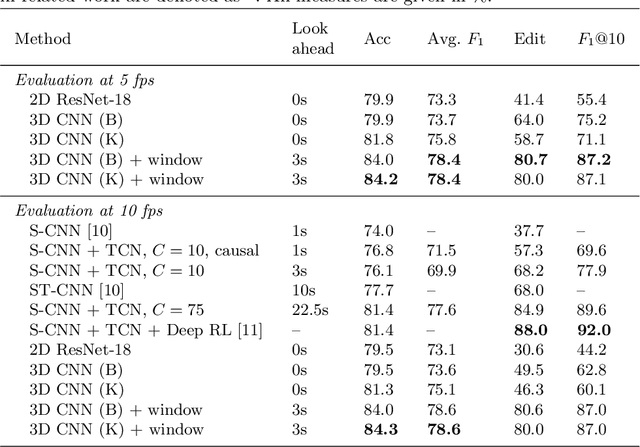
Automatically recognizing surgical gestures is a crucial step towards a thorough understanding of surgical skill. Possible areas of application include automatic skill assessment, intra-operative monitoring of critical surgical steps, and semi-automation of surgical tasks. Solutions that rely only on the laparoscopic video and do not require additional sensor hardware are especially attractive as they can be implemented at low cost in many scenarios. However, surgical gesture recognition based only on video is a challenging problem that requires effective means to extract both visual and temporal information from the video. Previous approaches mainly rely on frame-wise feature extractors, either handcrafted or learned, which fail to capture the dynamics in surgical video. To address this issue, we propose to use a 3D Convolutional Neural Network (CNN) to learn spatiotemporal features from consecutive video frames. We evaluate our approach on recordings of robot-assisted suturing on a bench-top model, which are taken from the publicly available JIGSAWS dataset. Our approach achieves high frame-wise surgical gesture recognition accuracies of more than 84%, outperforming comparable models that either extract only spatial features or model spatial and low-level temporal information separately. For the first time, these results demonstrate the benefit of spatiotemporal CNNs for video-based surgical gesture recognition.