 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Question Generation via Cross-Modal Self-Attention Networks Learning
Paper and Code
Jul 05, 2019
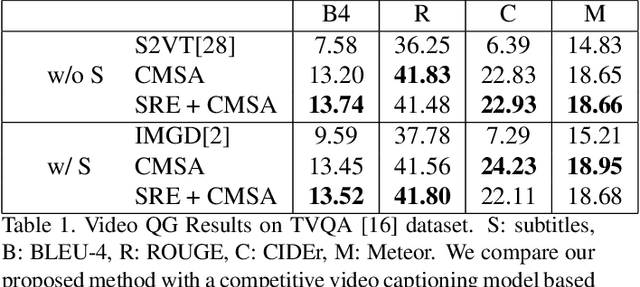
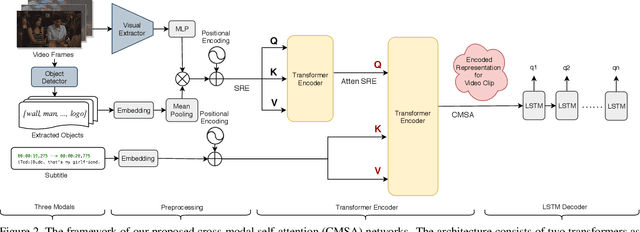
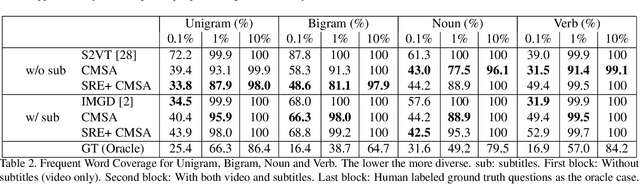
Video Question Answering (Video QA) is a critical and challenging task in multimedia comprehension. While deep learning based models are extremely capable of representing and understanding videos, these models heavily rely on massive data, which is expensive to label. In this paper, we introduce a novel task for automatically generating questions given a sequence of video frames and the corresponding subtitles from a clip of video to reduce the huge annotation cost. Learning to ask a question based on a video requires the model to comprehend the rich semantics in the scene and the interplay between the vision and the language. To address this, we propose a novel cross-modal self-attention (CMSA) network to aggregate the diverse features from video frames and subtitles. Excitingly, we demonstrate that our proposed model can improve the (strong) baseline from 0.0738 to 0.1374 in BLEU4 score -- more than 0.063 improvement (i.e., 85\% relatively). Most of all, We arguably pave a novel path toward solving the challenging Video QA task and provide detailed analysis which ushers the avenues for future investigations.