 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCascade Attention Guided Residue Learning GAN for Cross-Modal Translation
Paper and Code
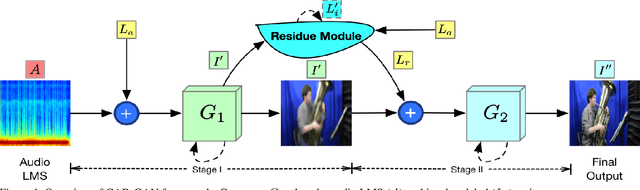

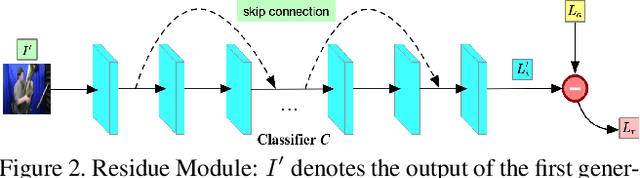
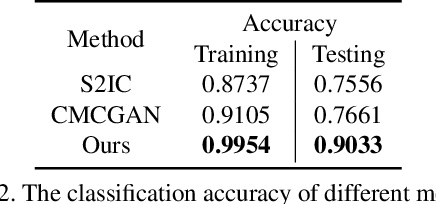
Since we were babies, we intuitively develop the ability to correlate the input from different cognitive sensors such as vision, audio, and text. However, in machine learning, this cross-modal learning is a nontrivial task because different modalities have no homogeneous properties. Previous works discover that there should be bridges among different modalities. From neurology and psychology perspective, humans have the capacity to link one modality with another one, e.g., associating a picture of a bird with the only hearing of its singing and vice versa. Is it possible for machine learning algorithms to recover the scene given the audio signal? In this paper, we propose a novel Cascade Attention-Guided Residue GAN (CAR-GAN), aiming at reconstructing the scenes given the corresponding audio signals. Particularly, we present a residue module to mitigate the gap between different modalities progressively. Moreover, a cascade attention guided network with a novel classification loss function is designed to tackle the cross-modal learning task. Our model keeps the consistency in high-level semantic label domain and is able to balance two different modalities. The experimental results demonstrate that our model achieves the state-of-the-art cross-modal audio-visual generation on the challenging Sub-URMP dataset. Code will be available at https://github.com/tuffr5/CAR-GAN.