 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHO-3D: A Multi-User, Multi-Object Dataset for Joint 3D Hand-Object Pose Estimation
Paper and Code


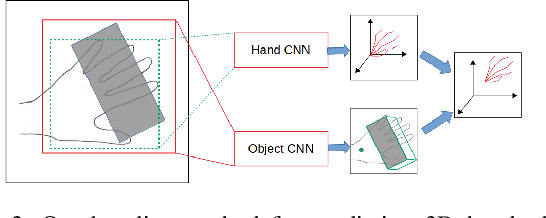

We propose a new dataset for 3D hand+object pose estimation from color images, together with a method for efficiently annotating this dataset, and a 3D pose prediction method based on this dataset. The current lack of training data makes the 3D hand+object pose estimation very challenging. This lack is due to the complexity of labeling many real images with both 3D poses and of generating synthetic images with various realistic interaction. Moreover, even if synthetic images could be used for training, annotated real images are still needed for validation. To tackle this challenge, we capture sequences with a simple setup made of a single RGB-D camera. We also use a color camera imaging the sequences from a side view, but only for validation. We introduce a novel method based on global optimization that exploits depth, color, and temporal constraints for efficiently annotating the sequences, which we use to train another novel method that predicts both the 3D poses of the hand and the object from a single color image. Our hope is to encourage other researchers to develop better annotation methods for our dataset: One can then apply such method to capture and easily annotate sequences captured with a single RGB-D camera to easily create additional training data thus solving one of the main problems of 3D hand+object pose estimation.