 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Preliminary Study on Data Augmentation of Deep Learning for Image Classification
Paper and Code
Jun 09, 2019
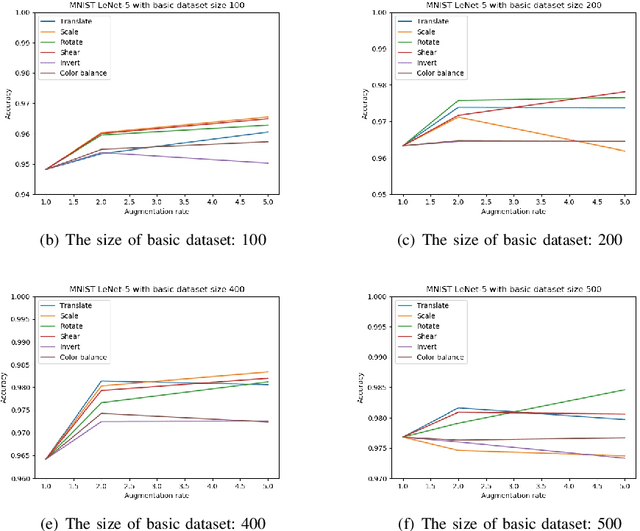
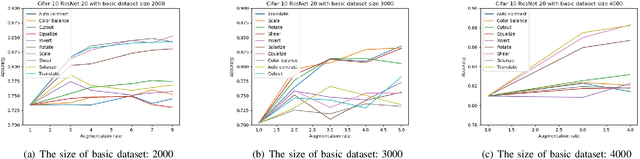
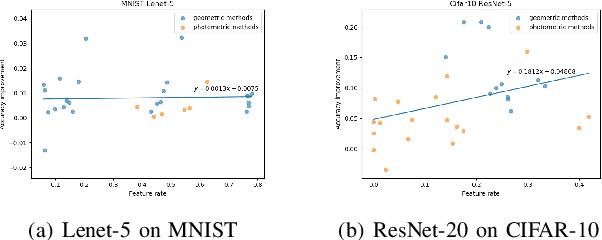
Deep learning models have a large number of freeparameters that need to be calculated by effective trainingof the models on a great deal of training data to improvetheir generalization performance. However, data obtaining andlabeling is expensive in practice. Data augmentation is one of themethods to alleviate this problem. In this paper, we conduct apreliminary study on how three variables (augmentation method,augmentation rate and size of basic dataset per label) can affectthe accuracy of deep learning for image classification. The studyprovides some guidelines: (1) it is better to use transformationsthat alter the geometry of the images rather than those justlighting and color. (2) 2-3 times augmentation rate is good enoughfor training. (3) the smaller amount of data, the more obviouscontributions could have.