 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards End-to-End Text Spotting in Natural Scenes
Paper and Code
Jun 17, 2019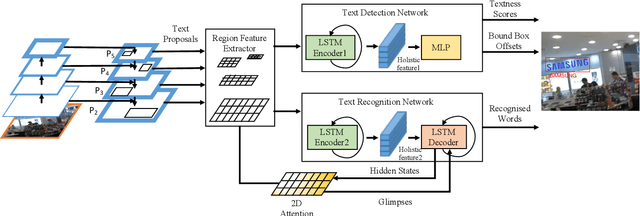
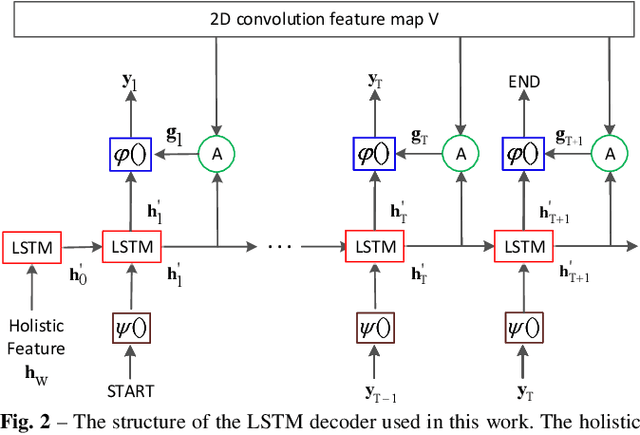


Text spotting in natural scene images is of great importance for many image understanding tasks. It includes two sub-tasks: text detection and recognition. In this work, we propose a unified network that simultaneously localizes and recognizes text with a single forward pass, avoiding intermediate processes such as image cropping and feature re-calculation, word separation, and character grouping. In contrast to existing approaches that consider text detection and recognition as two distinct tasks and tackle them one by one, the proposed framework settles these two tasks concurrently. The whole framework can be trained end-to-end and is able to handle text of arbitrary shapes. The convolutional features are calculated only once and shared by both detection and recognition modules. Through multi-task training, the learned features become more discriminate and improve the overall performance. By employing the $2$D attention model in word recognition, the irregularity of text can be robustly addressed. It provides the spatial location for each character, which not only helps local feature extraction in word recognition, but also indicates an orientation angle to refine text localization. Our proposed method has achieved state-of-the-art performance on several standard text spotting benchmarks, including both regular and irregular ones.