 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaceSwapNet: Landmark Guided Many-to-Many Face Reenactment
Paper and Code

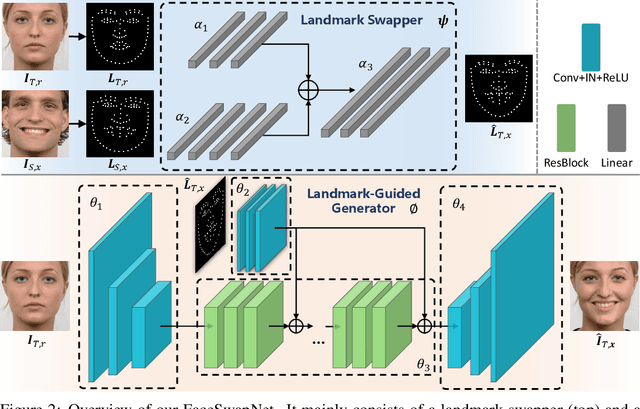
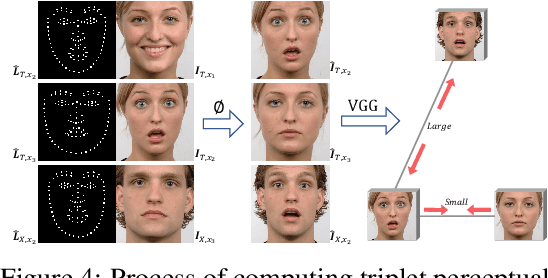
Recent face reenactment studies have achieved remarkable success either between two identities or in the many-to-one task. However, existing methods have limited scalability when the target person is not a predefined specific identity. To address this limitation, we present a novel many-to-many face reenactment framework, named FaceSwapNet, which allows transferring facial expressions and movements from one source face to arbitrary targets. Our proposed approach is composed of two main modules: the landmark swapper and the landmark-guided generator. Instead of maintaining independent models for each pair of person, the former module uses two encoders and one decoder to adapt anyone's face landmark to target persons. Using the neutral expression of the target person as a reference image, the latter module leverages geometry information from the swapped landmark to generate photo-realistic and emotion-alike images. In addition, a novel triplet perceptual loss is proposed to force the generator to learn geometry and appearance information simultaneously. We evaluate our model on RaFD dataset and the results demonstrate the superior quality of reenacted images as well as the flexibility of transferring facial movements between identities.