 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSQIL: Imitation Learning via Regularized Behavioral Cloning
Paper and Code

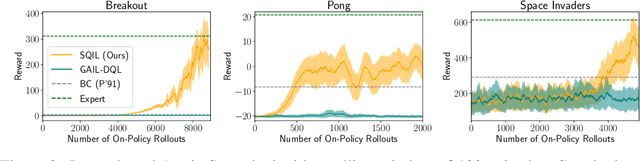
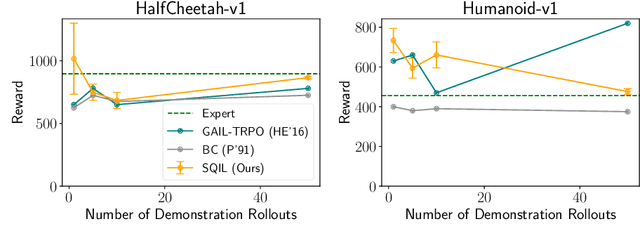

Learning to imitate expert behavior given action demonstrations containing high-dimensional, continuous observations and unknown dynamics is a difficult problem in robotic control. Simple approaches based on behavioral cloning (BC) suffer from state distribution shift, while more complex methods that generalize to out-of-distribution states can be difficult to use, since they typically involve adversarial optimization. We propose an alternative that combines the simplicity of BC with the robustness of adversarial imitation learning. The key insight is that under the maximum entropy model of expert behavior, BC corresponds to fitting a soft Q function that maximizes the likelihood of observed actions. This perspective suggests a way to regularize BC so that it generalizes to out-of-distribution states: combine the standard maximum-likelihood objective with a penalty on the soft Bellman error of the soft Q function. We show that this penalty term gives the agent an incentive to take actions that lead it back to demonstrated states when it encounters new states. Experiments show that our method outperforms BC and GAIL on a variety of image-based and low-dimensional environments in Box2D, Atari, and MuJoCo.