 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOVSNet : Towards One-Pass Real-Time Video Object Segmentation
Paper and Code
May 24, 2019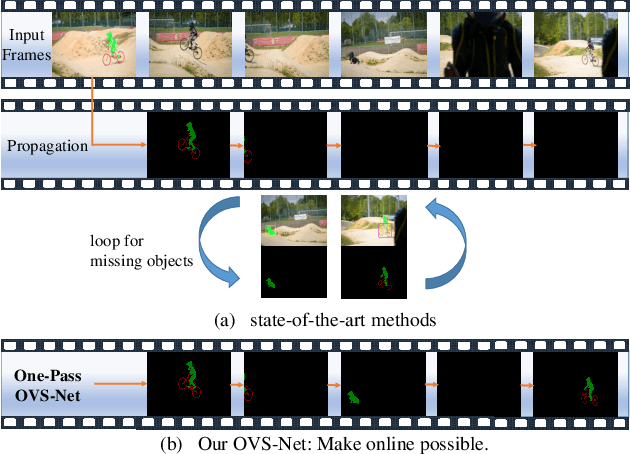
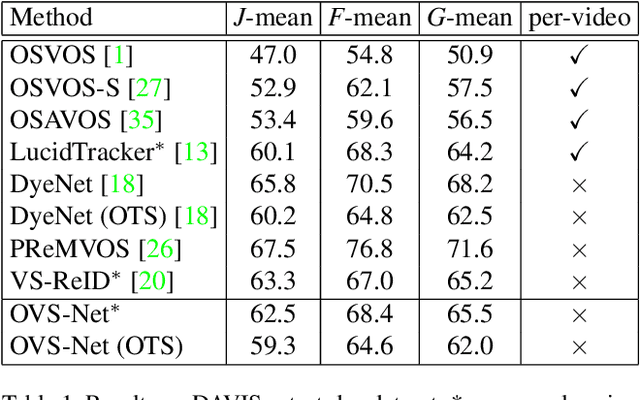
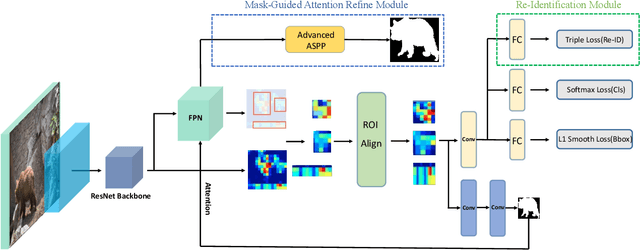
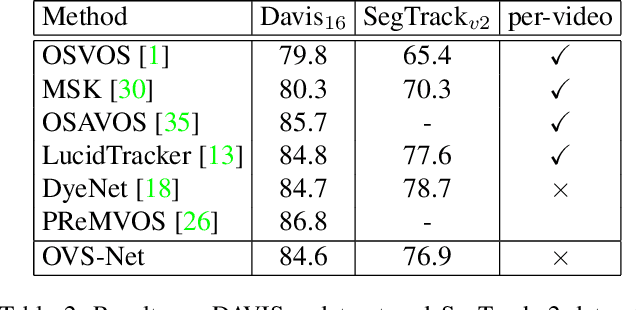
Video object segmentation aims at accurately segmenting the target object regions across consecutive frames. It is technically challenging for coping with complicated factors (e.g., shape deformations, occlusion and out of the lens). Recent approaches have largely solved them by using backforth re-identification and bi-directional mask propagation. However, their methods are extremely slow and only support offline inference, which in principle cannot be applied in real time. Motivated by this observation, we propose a new detection-based paradigm for video object segmentation. We propose an unified One-Pass Video Segmentation framework (OVS-Net) for modeling spatial-temporal representation in an end-to-end pipeline, which seamlessly integrates object detection, object segmentation, and object re-identification. The proposed framework lends itself to one-pass inference that effectively and efficiently performs video object segmentation. Moreover, we propose a mask guided attention module for modeling the multi-scale object boundary and multi-level feature fusion. Experiments on the challenging DAVIS 2017 demonstrate the effectiveness of the proposed framework with comparable performance to the state-of-the-art, and the great efficiency about 11.5 fps towards pioneering real-time work to our knowledge, more than 5 times faster than other state-of-the-art methods.