 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobiVSR: A Visual Speech Recognition Solution for Mobile Devices
Paper and Code
Jun 05, 2019
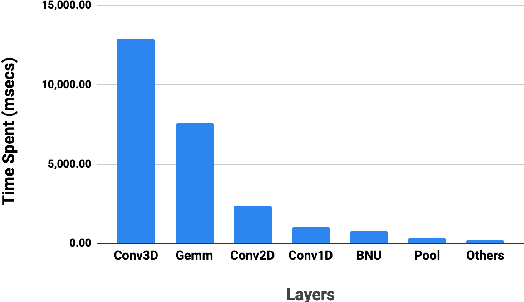
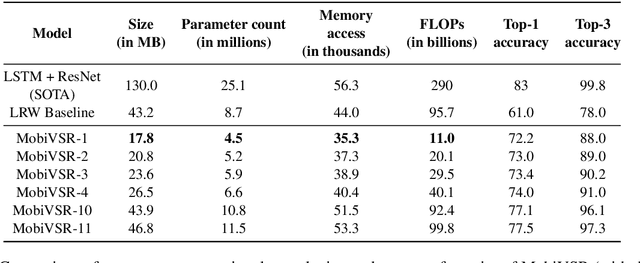
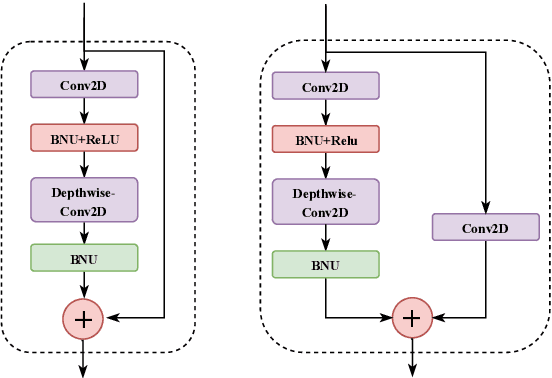
Visual speech recognition (VSR) is the task of recognizing spoken language from video input only, without any audio. VSR has many applications as an assistive technology, especially if it could be deployed in mobile devices and embedded systems. The need of intensive computational resources and large memory footprint are two of the major obstacles in developing neural network models for VSR in a resource constrained environment. We propose a novel end-to-end deep neural network architecture for word level VSR called MobiVSR with a design parameter that aids in balancing the model's accuracy and parameter count. We use depthwise-separable 3D convolution for the first time in the domain of VSR and show how it makes our model efficient. MobiVSR achieves an accuracy of 73\% on a challenging Lip Reading in the Wild dataset with 6 times fewer parameters and 20 times lesser memory footprint than the current state of the art. MobiVSR can also be compressed to 6 MB by applying post training quantization.