 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel BiLevel Paradigm for Image-to-Image Translation
Paper and Code

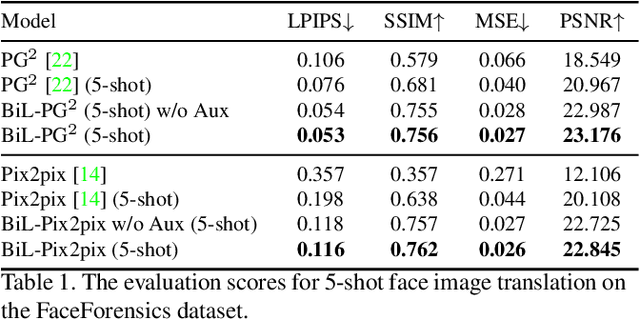
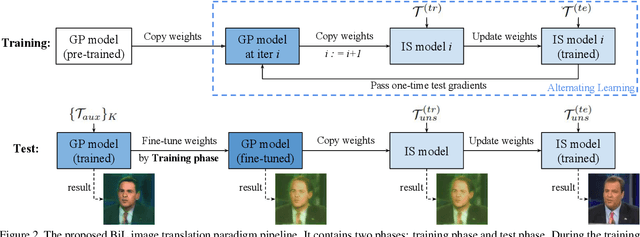
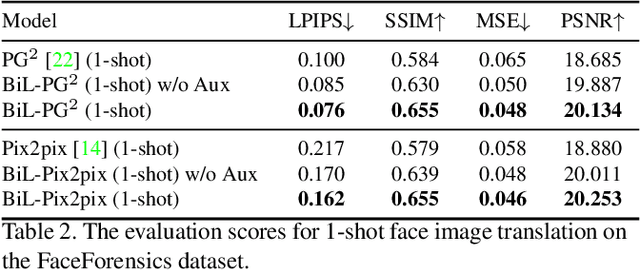
Image-to-image (I2I) translation is a pixel-level mapping that requires a large number of paired training data and often suffers from the problems of high diversity and strong category bias in image scenes. In order to tackle these problems, we propose a novel BiLevel (BiL) learning paradigm that alternates the learning of two models, respectively at an instance-specific (IS) and a general-purpose (GP) level. In each scene, the IS model learns to maintain the specific scene attributes. It is initialized by the GP model that learns from all the scenes to obtain the generalizable translation knowledge. This GP initialization gives the IS model an efficient starting point, thus enabling its fast adaptation to the new scene with scarce training data. We conduct extensive I2I translation experiments on human face and street view datasets. Quantitative results validate that our approach can significantly boost the performance of classical I2I translation models, such as PG2 and Pix2Pix. Our visualization results show both higher image quality and more appropriate instance-specific details, e.g., the translated image of a person looks more like that person in terms of identity.