 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding a mixed-lingual neural TTS system with only monolingual data
Paper and Code
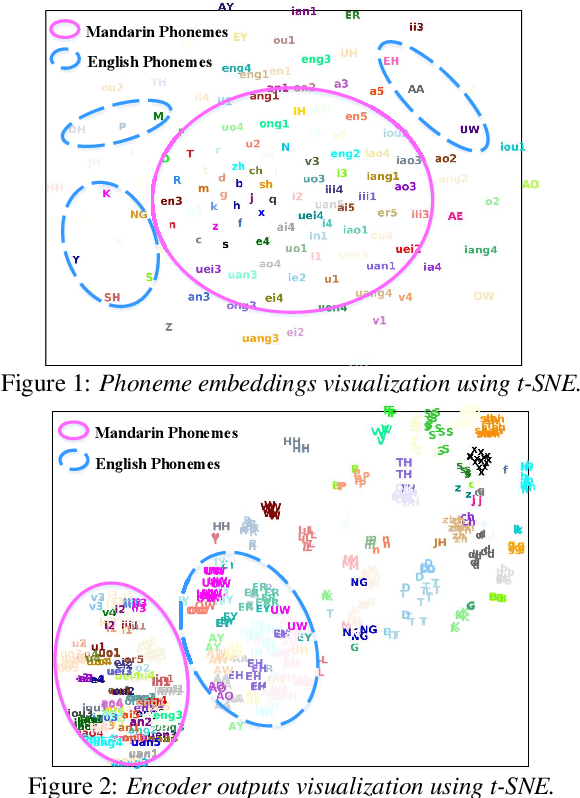
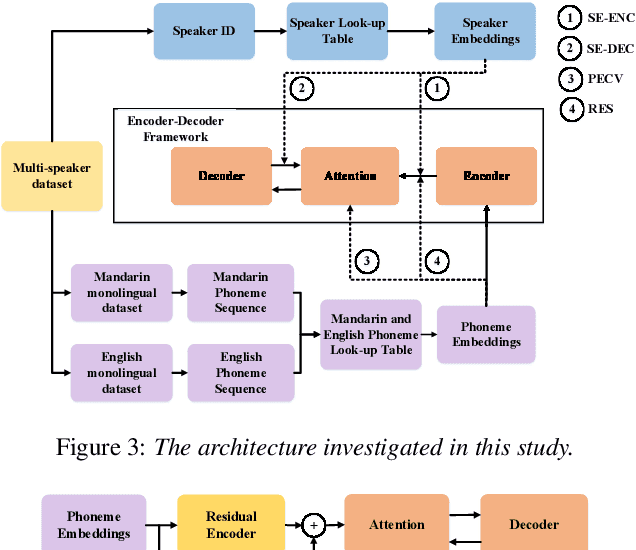

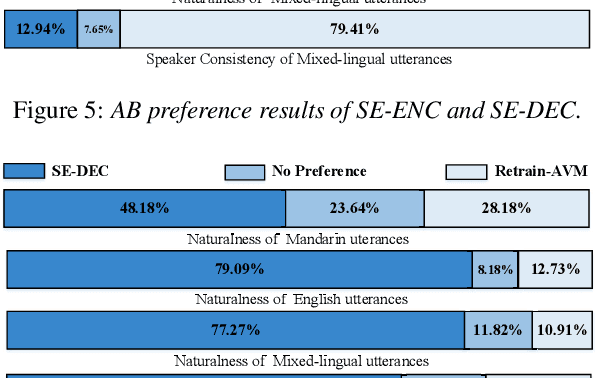
When deploying a Chinese neural text-to-speech (TTS) synthesis system, one of the challenges is to synthesize Chinese utterances with English phrases or words embedded. This paper looks into the problem in the encoder-decoder framework when only monolingual data from a target speaker is available. Specifically, we view the problem from two aspects: speaker consistency within an utterance and naturalness. We start the investigation with an Average Voice Model which is built from multi-speaker monolingual data, i.e. Mandarin and English data. On the basis of that, we look into speaker embedding for speaker consistency within an utterance and phoneme embedding for naturalness and intelligibility and study the choice of data for model training. We report the findings and discuss the challenges to build a mixed-lingual TTS system with only monolingual data.