 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Sound of Motions
Paper and Code
Apr 11, 2019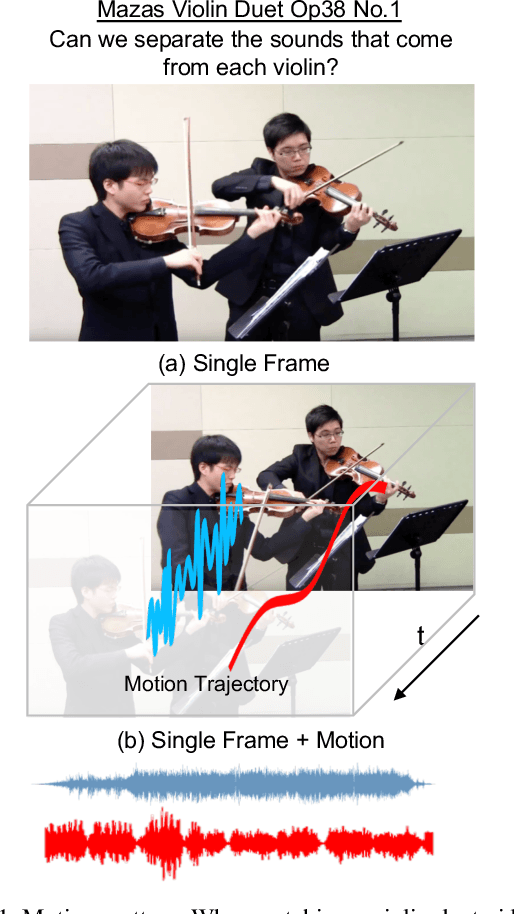
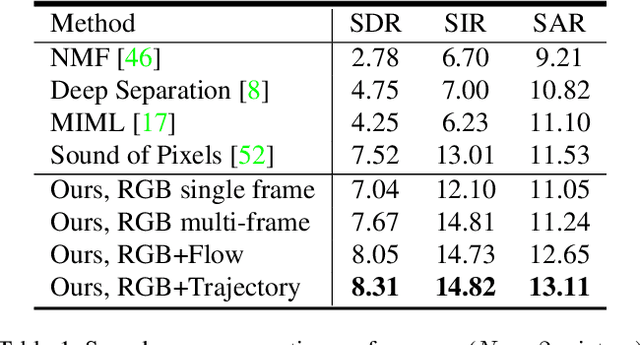
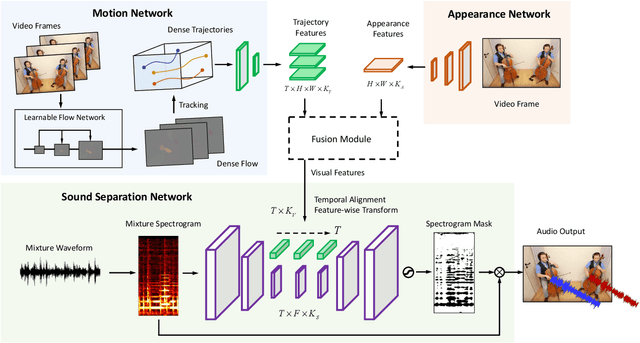
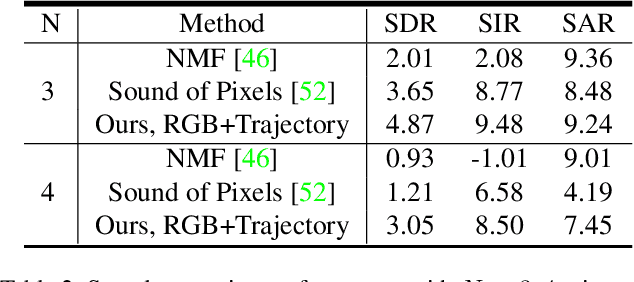
Sounds originate from object motions and vibrations of surrounding air. Inspired by the fact that humans is capable of interpreting sound sources from how objects move visually, we propose a novel system that explicitly captures such motion cues for the task of sound localization and separation. Our system is composed of an end-to-end learnable model called Deep Dense Trajectory (DDT), and a curriculum learning scheme. It exploits the inherent coherence of audio-visual signals from a large quantities of unlabeled videos. Quantitative and qualitative evaluations show that comparing to previous models that rely on visual appearance cues, our motion based system improves performance in separating musical instrument sounds. Furthermore, it separates sound components from duets of the same category of instruments, a challenging problem that has not been addressed before.