 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRanking-Based Autoencoder for Extreme Multi-label Classification
Paper and Code
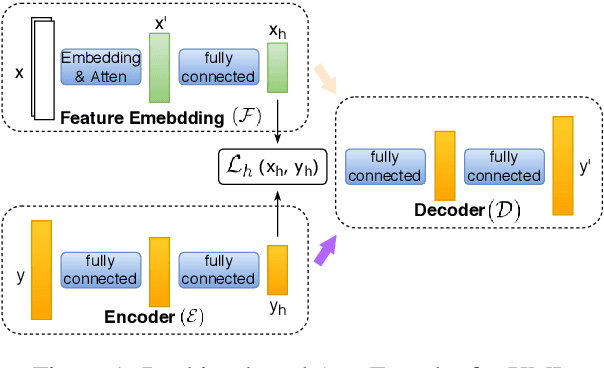
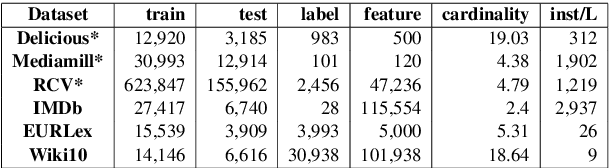
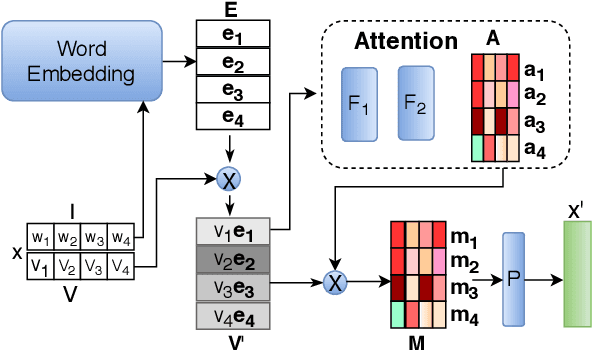
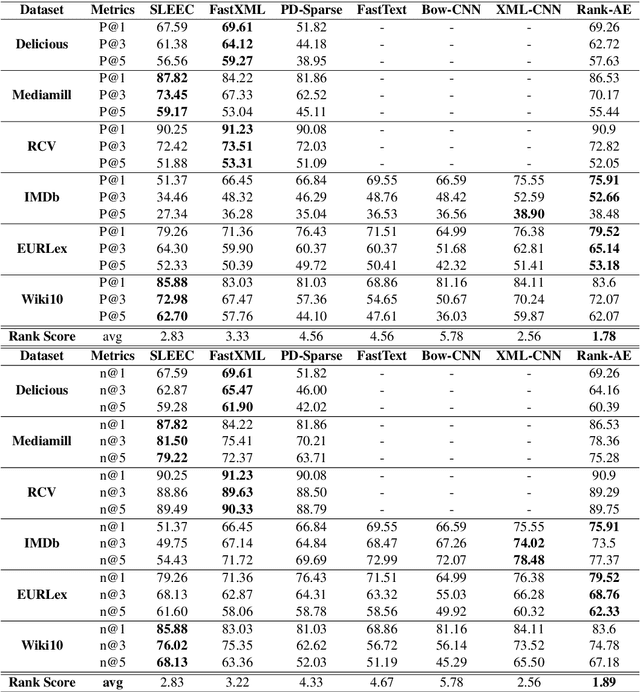
Extreme Multi-label classification (XML) is an important yet challenging machine learning task, that assigns to each instance its most relevant candidate labels from an extremely large label collection, where the numbers of labels, features and instances could be thousands or millions. XML is more and more on demand in the Internet industries, accompanied with the increasing business scale / scope and data accumulation. The extremely large label collections yield challenges such as computational complexity, inter-label dependency and noisy labeling. Many methods have been proposed to tackle these challenges, based on different mathematical formulations. In this paper, we propose a deep learning XML method, with a word-vector-based self-attention, followed by a ranking-based AutoEncoder architecture. The proposed method has three major advantages: 1) the autoencoder simultaneously considers the inter-label dependencies and the feature-label dependencies, by projecting labels and features onto a common embedding space; 2) the ranking loss not only improves the training efficiency and accuracy but also can be extended to handle noisy labeled data; 3) the efficient attention mechanism improves feature representation by highlighting feature importance. Experimental results on benchmark datasets show the proposed method is competitive to state-of-the-art methods.