 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccurate Monocular 3D Object Detection via Color-Embedded 3D Reconstruction for Autonomous Driving
Paper and Code
Apr 01, 2019
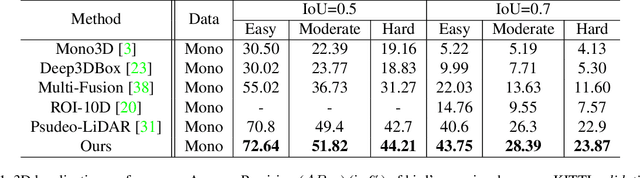
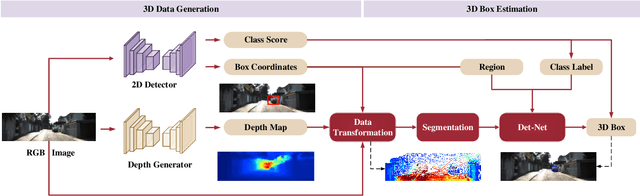
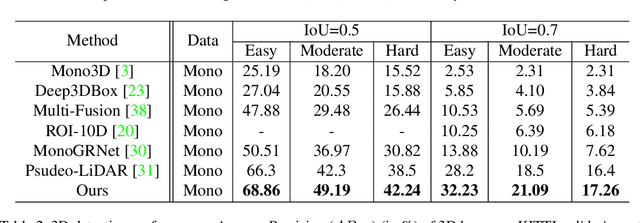
In this paper, we propose a monocular 3D object detection framework in the domain of autonomous driving. Unlike previous image-based methods which focus on RGB feature extracted from 2D images, our method solves this problem in the reconstructed 3D space in order to exploit 3D contexts explicitly. To this end, we first leverage a stand-alone module to transform the input data from 2D image plane to 3D point clouds space for a better input representation, then we perform the 3D detection using PointNet backbone net to obtain objects 3D locations, dimensions and orientations. To enhance the discriminative capability of point clouds, we propose a multi-modal feature fusion module to embed the complementary RGB cue into the generated point clouds representation. We argue that it is more effective to infer the 3D bounding boxes from the generated 3D scene space (i.e., X,Y, Z space) compared to the image plane (i.e., R,G,B image plane). Evaluation on the challenging KITTI dataset shows that our approach boosts the performance of state-of-the-art monocular approach by a large margin, i.e., around 15% absolute AP on both 3D localization and detection tasks for Car category at 0.7 IoU threshold.