 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRectified Decision Trees: Towards Interpretability, Compression and Empirical Soundness
Paper and Code
Mar 14, 2019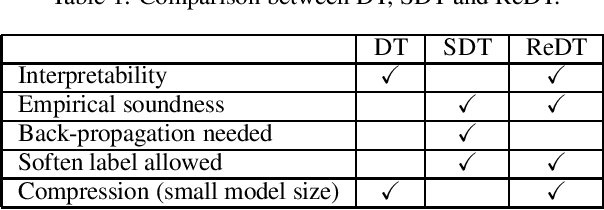

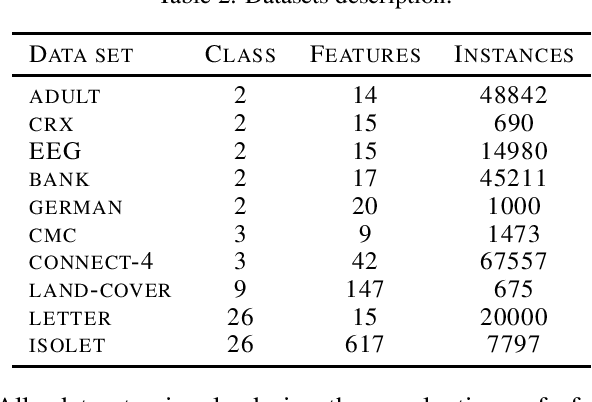
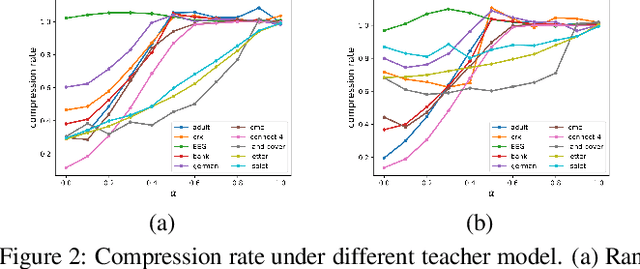
How to obtain a model with good interpretability and performance has always been an important research topic. In this paper, we propose rectified decision trees (ReDT), a knowledge distillation based decision trees rectification with high interpretability, small model size, and empirical soundness. Specifically, we extend the impurity calculation and the pure ending condition of the classical decision tree to propose a decision tree extension that allows the use of soft labels generated by a well-trained teacher model in training and prediction process. It is worth noting that for the acquisition of soft labels, we propose a new multiple cross-validation based method to reduce the effects of randomness and overfitting. These approaches ensure that ReDT retains excellent interpretability and even achieves fewer nodes than the decision tree in the aspect of compression while having relatively good performance. Besides, in contrast to traditional knowledge distillation, back propagation of the student model is not necessarily required in ReDT, which is an attempt of a new knowledge distillation approach. Extensive experiments are conducted, which demonstrates the superiority of ReDT in interpretability, compression, and empirical soundness.